







SC24: Hammerspace Transforms GPU Computing Infrastructure as First to Unlock New Tier of Fast Shared Storage
Cuts storage costs, slashes power use and drives GPUs to peak performance.
This is a Press Release edited by StorageNewsletter.com on November 15, 2024 at 2:03 pmHammerspace, Inc. introduced the latest version of its Global Data Platform software, unlocking a new tier of storage by transforming local NVMe storage on GPU servers into a tier-0 of fast, persistent shared storage. By activating this previously ‘stranded’ local NVMe storage seamlessly into the Global Data Platform, tier-0 delivers data directly to GPUs at local NVMe speeds, unleashing untapped potential and redefining both GPU computing performance and storage efficiency.
![]()
With tier-0, organizations can now fully leverage the local NVMe on GPU servers as a high-performance shared resource with the same redundancy and protection as traditional external storage. This integration makes the server local NVMe capacity part of a unified parallel global file system, seamlessly spanning all storage types with automated data orchestration for greater efficiency and flexibility.
Utilizing this otherwise unused high-performance storage, tier-0 reduces the amount of expensive external storage systems organizations need to buy, slashes power requirements and reclaims valuable data center space. This breakthrough leverages the already sunk investment and deployed capacity in existing NVMe storage within the GPU servers, maximizing utilization and accelerating time to value.
“Tier-0 represents a monumental leap in GPU computing, empowering organizations to harness the of their existing infrastructure. By unlocking stranded NVMe storage, we are not just enhancing performance – we’re redefining the possibilities of data orchestration in high-performance computing,” said David Flynn, founder and CEO. “This technology allows innovators to push the boundaries of AI and HPC, accelerating time to value and enabling breakthroughs that can shape the future.”
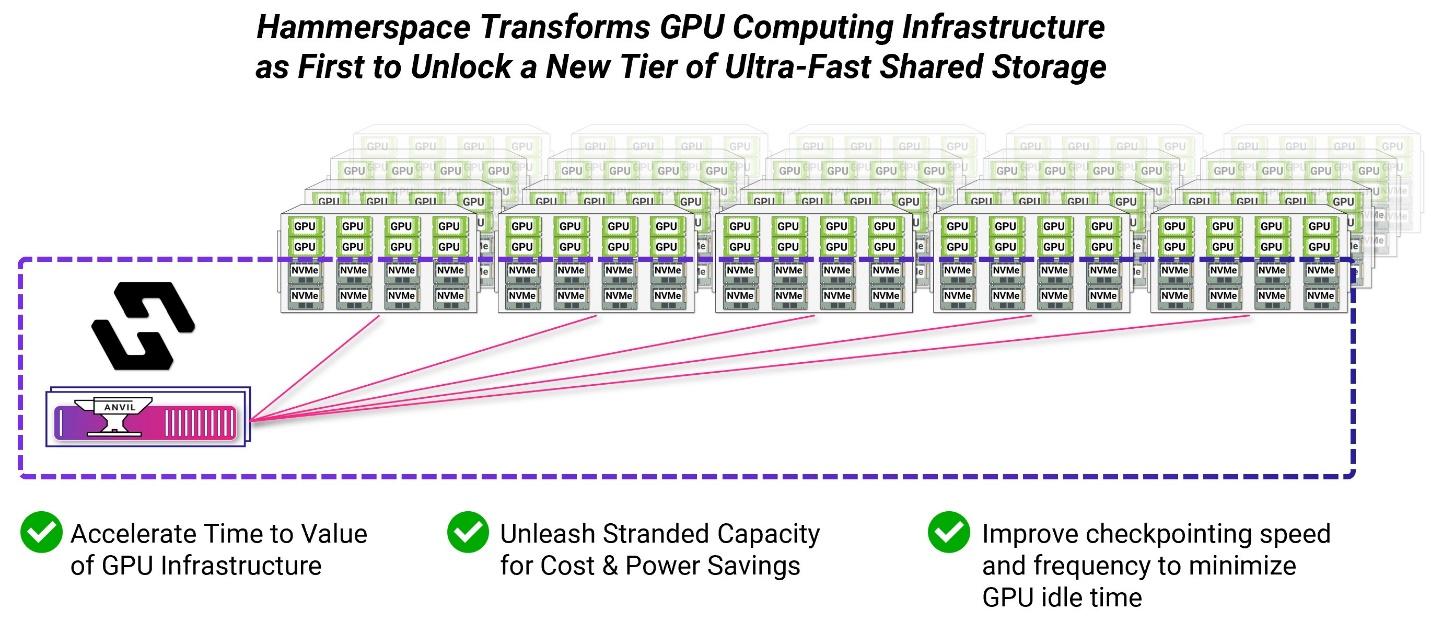
Accelerate Time to Value of GPU Infrastructure
By leveraging unused capacity on their GPU servers with tier-0, organizations can get their workflows up and running in production immediately, even before configuring external shared storage systems. By harnessing the existing NVMe storage within their deployed GPU servers, companies can reduce setup time, enabling teams to start their GPU computing projects almost immediately. This swift integration allows for rapid experimentation and deployment, facilitating faster time to value as data scientists and engineers can focus on innovation rather than infrastructure.
Unleash Stranded Capacity for Cost and Power Savings
As organizations expand GPU environments for AI training, HPC, and unstructured data processing, the local NVMe storage in GPU servers is typically largely unused for the compute workflows as it is siloed and lacks shared access and built-in reliability features.
With tier-0, the vendor turns isolated NVMe into a high-performance shared resource, reducing power demands for that storage capacity by approximately 95% compared with deploying external networking and storage. Accessible via a global, multi-protocol namespace, it spans silos, sites, and clouds, enabling seamless data access for users and applications. This integration keeps active datasets local to GPU servers, allows AI model checkpoints to be written locally, and automates tiering across tier-0, tier-1 and tier-2 storage.
Tier-0 enables the storage capacity in GPU servers to be incorporated into the Global Data Platform in minutes, making this storage capacity available almost instantly. Through Hammerspace Data Orchestration, data protection, tiering, and global data services are fully automated across on-premises and cloud storage.
By seamlessly integrating local NVMe as part of a unified global file system, the company makes files and objects stored on GPU servers available to other clients and orchestrated intelligently across all storage tiers. And, as with all firm’s innovations, no proprietary software or modifications are required on the client or GPU server – everything operates within the Linux kernel using standard protocols.
Maximize GPU Efficiency with Lightning-Fast Checkpointing
Tier-0 rewrites the rules for storage speed, unlocking a new era of efficiency in GPU computing. By streamlining data handling and accelerating checkpointing times up to 10x faster than external storage, tier-0 eliminates the lag that’s been holding back GPU utilization. With every second shaved off checkpointing, GPU resources are freed up to tackle other tasks, translating to real cost savings and up to 20% more output from existing investments. In large GPU clusters, this adds up to millions in recaptured value – an essential breakthrough for any organization serious about harnessing the power of high-performance computing.
Unveiling Hammerspace Global Data Platform Software v5.1
Click to enlarge
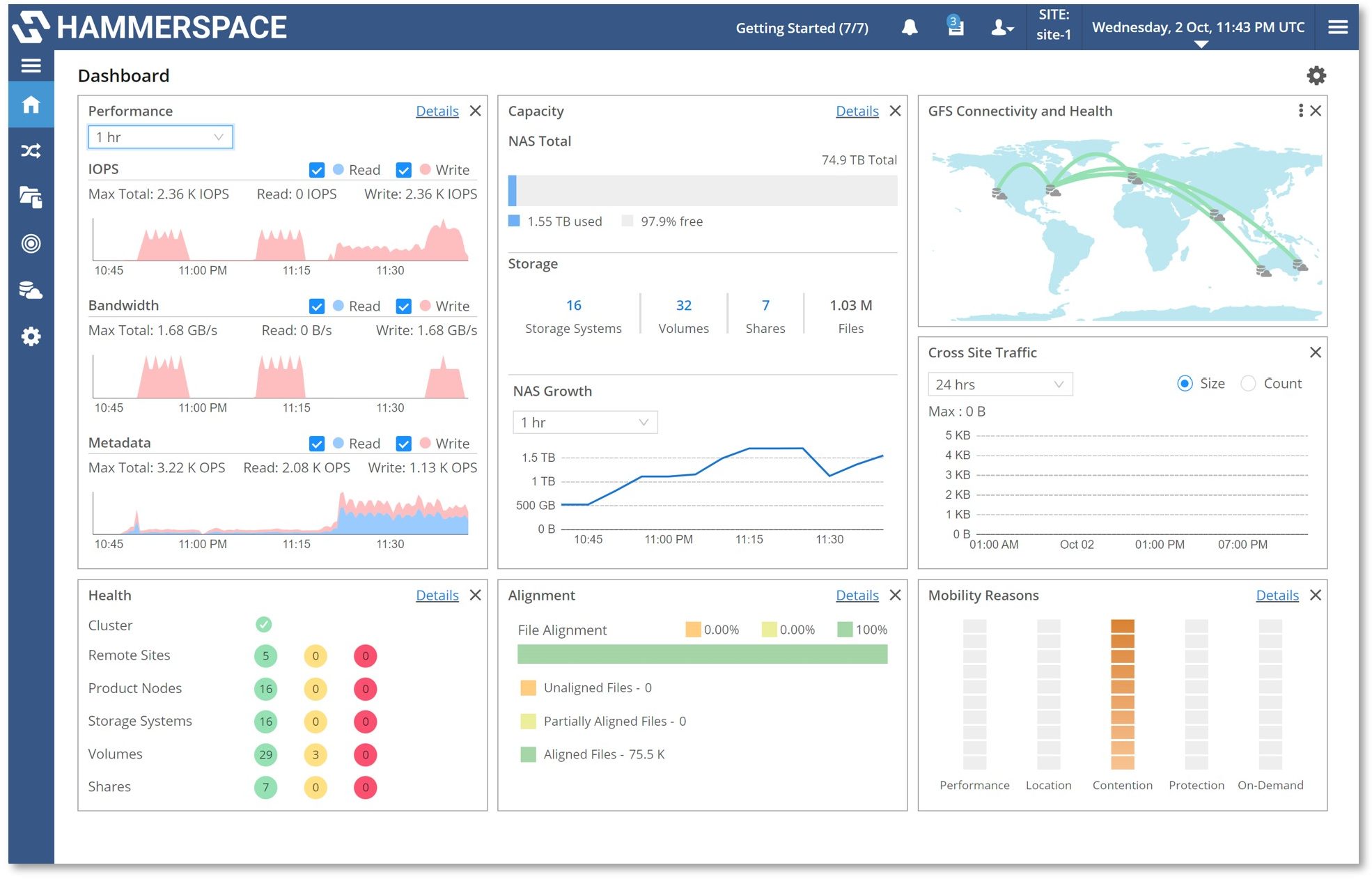
The latest version of firm’s software also provides a number of additional new features and capabilities that improve performance, connectivity and ease of use, including:
- Native client-side S3 protocol support – Provides unified permissions and namespace with NFS & SMB file protocols with extreme scalability.
- Significant platform performance improvements, with 2x for metadata and over 5x for data mobility, data-in-place assimilation and cloud-bursting.
- Additional resiliency features with three-way HA for Hammerspace metadata servers.
- Automated failover improvements across multiple clusters and sites.
- New Objectives (policy-based automation) and refinements to existing Objectives.
- Significant updates to the Hammerspace GUI, including new tile-based dashboards that may be customized per user, with richer controls.
- Enhancements to client-side SMB file protocol.
- High availability when deployed in Google Cloud Platform.
The advancements in Global Data Platform are more than just a revolution in storage; they are a catalyst for innovation in GPU computing. By transforming how organizations leverage their infrastructure, we’re paving the way for unprecedented advancements in AI and high-performance computing. As we continue to orchestrate the next data cycle, the company is poised to lead the charge into a new era of efficiency and performance.
Learn More
Executive Brief: Unlocking a New Tier 0 of Ultra-Fast Shared Storage
Technical Brief: Improving Performance, Efficiency, ROI of GPU Computing with Tier 0
Whitepaper: A Detailed Analysis of Using Hammerspace Tier 0 for Checkpointing
Webinar: Unleash the Full Potential of Your GPU Servers
Blog: Introducing Hammerspace Tier 0
Technical Brief: Native Object Access Meets Parallel FS Performance
Technical Brief: Data-in-Place Assimilation of Object Data
“The demand for compute power is constantly growing as use cases for HPC rapidly expand. Yet, budget and power remain constraints. Hammerspace’s Tier 0 unlocks a new level of efficiency, allowing us to reallocate resources already within our compute rather than investing in additional storage infrastructure,” said Chris Sullivan, director of research and academic computing at Oregon State University. “This approach not only accelerates research by maximizing existing infrastructure but also aligns with our sustainability goals by reducing energy consumption and data center footprint.”
“Integrating Hammerspace’s tier-0 storage into GPU orchestration environments brings a transformative leap in performance and efficiency for our customers,” said Matthew Shaxted, founder and CEO of Parallel Works, Inc. “By unlocking local NVMe storage within GPU servers as a high-speed, shared resource, tier-0 maximizes the compute potential of every GPU cycle. This innovation enables our customers to run demanding workloads, like AI training and HPC, faster and more efficiently than ever, with streamlined data access across environments. Together, Hammerspace and Parallel Works are empowering organizations to accelerate their AI and data-driven initiatives with the bottlenecks of traditional decentralized infrastructure.”
“We have many customers that are deploying large GPU clusters, and by making the local GPU server storage available as a new tier of high-performance shared storage, Hammerspace is adding a huge value to these customers,” says Scot Colmer, field CTO, AI of Computacenter plc. “The ROI of the Hammerspace tier-0 solution is really compelling – delivering massive cost savings and power savings to our customers and decreasing GPU idle time.”
Comments
Many GPU users dream about it and now it's possible. They imagine to pool that GPU connected storage zone with other storage entity via any mechanism but in fact nobody really spent time to develop a solution at least publicly until now. Until the Flynn band entered the game, who very often surprised and shook the market with an answer, a good one many times, confirming that this company really spends time to solve users' challenges with tailored solutions.
And what the 5.1 release of Hammerspace Global Data Platform does is exactly that, they group all these discreet local NVMe storage provided with GPU systems within the shared global file storage pool. They name this NVMe local attached storage tier-0 and again it illustrates perfectly the place and role of these entities that can represent a very large storage space at scale, we mean, at hyperscale.
Click to enlarge
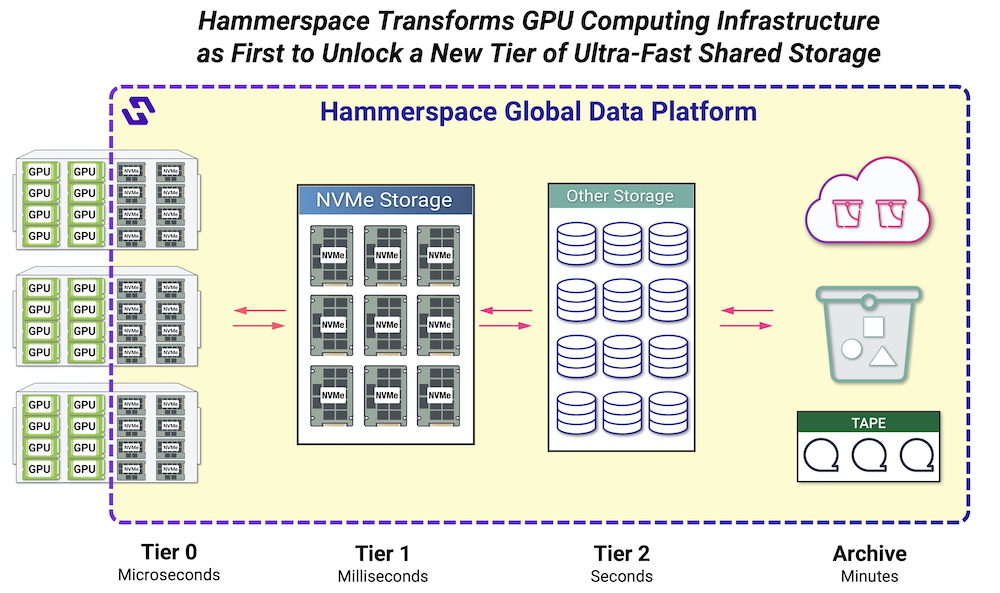
The impact of such "new service" is huge, first on the performance side and second on the money people left on tables before adopting such model. In other words, the ROI is immediate and significant.
The value comes from a few key elements we wish to insist on. First, this storage espace is no longer "lost", second these isolated drives are grouped together and third they're connected to the global pool leveraging NFS standard protocol and finally the 2 advantages mentioned above about performance and cost. No doubt, the gain is massive and will change how users will now consider GPU storage. One of the key applications of such development is for checkpointing being a fundamental service for GPU-based infrastructure.
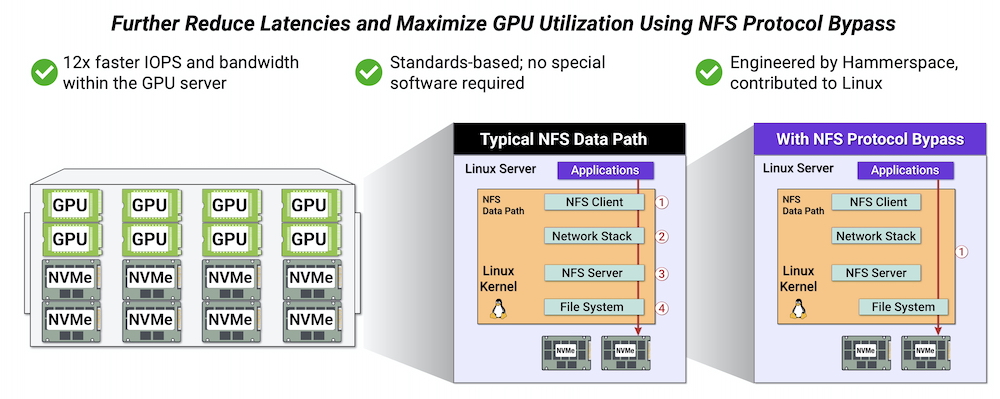
The beauty of this was not straightforward as classic NFS implementation would have introduce some latency in that specific case. To finally touch the Graal, it was mandatory to adapt the NFS protocol on the client side and introduce some NFS protocol bypass in the data path within the Linux kernel. This is what is named LOCALIO when the client and server reside on the same node. The network RPC/XDR protocol is then useless in that case and avoiding these layers produce big performance gains in the 10x order of magnitude. It is useful with GPU here but also when configurations use containers on the same host. And as Hammerspace is a key contributor to the NFS standard, this client side NFS code was merged into Linux 6.12 release.
Click to enlarge
In addition, the product team refreshed the GUI with dynamic customized panes and it looks superb.
The other key new improvement is related to the S3 protocol consumed by clients from the Hammerspace service layer. The redesign is related to performance. Up to 60 nodes can expose S3 concurrently even if a file is entirely send/read to/from one node. The S3 infrastructure offers a global S3 service but to insist on this, there is no chunking across S3 heads as it would require some changes on S3 above, on the client or on the network part. But with a load balancer, users can leverage this uniform S3 service and distribute files horizontally and improve SLAs.
The fact that the company is installed at META data center puts pressure on the development team as challenges in the AI domain are so big. There is clearly a race among these large hyperscalers...
We'll see how the competition will react to this pretty brilliant idea regarding the tier-0 approach, the 2nd improvement is now generally available. SC24 is in a few days in Atlanta, GA, and we're sure many people will speak about this news.






 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter


