







Recap of 57th IT Press Tour in Istanbul, Turkey
With 6 companies: Cleondris, Datashelter, EU eArchiving Initiative, Hopsworks, MooseFS and ZeroPoint Technologies
By Philippe Nicolas | September 27, 2024 at 2:00 pm This article has been written by Philippe Nicolas, initiator, conceptor and co-organizer of the event launched in 2009.
This article has been written by Philippe Nicolas, initiator, conceptor and co-organizer of the event launched in 2009.
![]()
This 57th edition of The IT Press Tour took place in Istanbul, Turkey, early September and all the press group and organizations had time exchanging about IT infrastructure, cloud, networking, security, data management and storage and of course AI present across all these topics. Six companies have been met, they are Cleondris, Datashelter, EU eArchiving Initiative, Hopsworks, MooseFS and ZeroPoint Technologies.
Cleondris
Second participation for Cleondris who chose to unveil its new cybersecurity software solution dedicated to NetApp filers. The Swiss software company, launched in 2009, develops special add-on software solutions for the NetApp ecosystem and filers. Christian Plattner, founder and CEO, announced Cleondris ONE to improve protection vs. ransomware, before the official public launch in Las Vegas, NV, during the annual NetApp Insight user conference next week.
Often seen as a close environment, NetApp receives Cleondris intelligent software layer that brings new open advanced solutions to augment filers’ services and here especially in the security space.
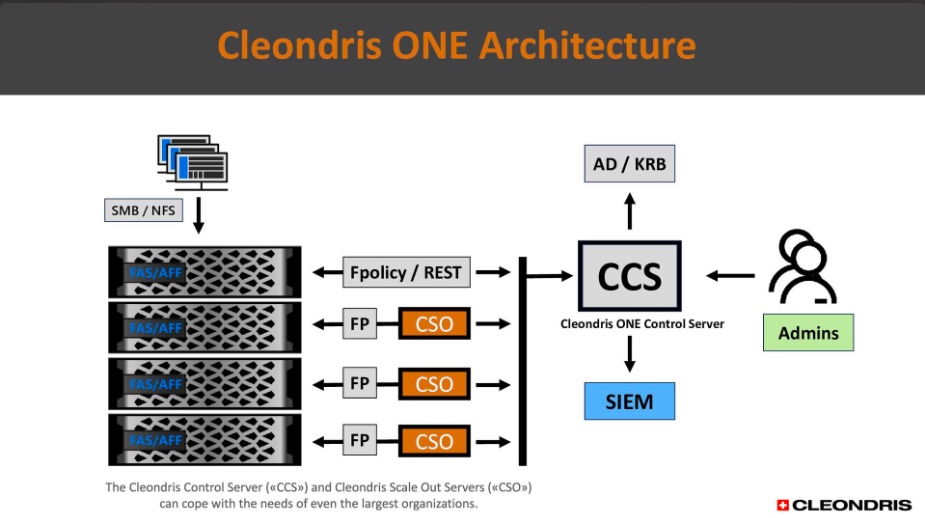
Cleondris ONE goals are to protect, detect but also prevent cyber threats and therefore disasters with some new resilience models coupling 3 key services – backup, security and compliance – into one unified solution.
The product is delivered as an OVA image and deployed on a dedicated appliance. Integrated via the Fpolicy mechanism running ONTAP 9, 10 and up on-premises, also supporting Amazon FSx for NetApp and Cloud Volumes ONTAP for cloud flavors, Cleondris ONE operates with single node or large clusters. It leverages AI based ONTAP Autonomous Ransomware Protection and adds other methods around filename patterns, behavior analysis and file verification to make frequent audits. These audits are stored as a blockchain displayed on a rich GUI and serve as the base of the solution using immutable backups and air-gapped snapshots. The granularity is the file, all is controlled by the Granular Cyber Restore.
More globally, backup is a serious method to provide data redundancy but alone it doesn’t solve any ransomware specific tasks. It requires additional code to provide pattern detection, potentially prevention and trigger some rapid recovery. Here again the audits allows to detect data divergence and thus start some recovery mechanims. CDP, near CDP or frequent snapshots are key to align with some compliance needs or just satisfy some RPO goals.
Datashelter
SaaS applications offer opportunities for a variety of projects as the subscription is so easy and rapid. And it also exposes data at risk as many users don’t pay attention on the data protection. This challenge exists for all type of companies.
Very young french backup software company founded in 2023, the entity develops a SaaS backup solution for SMB. With a very small team based in Toulouse, France, the organization has already secured more than 50 customers. The original idea came from the observation of lack of solution for small businesses or solutions with unpredictable pricing and also the need to consider some secondary storage, on-premises or cloud-based, for non technical people. But the real trigger was the scandal happened at OVHcloud in its datacenter in Strasbourg and the impact it had on small web-based businesses.
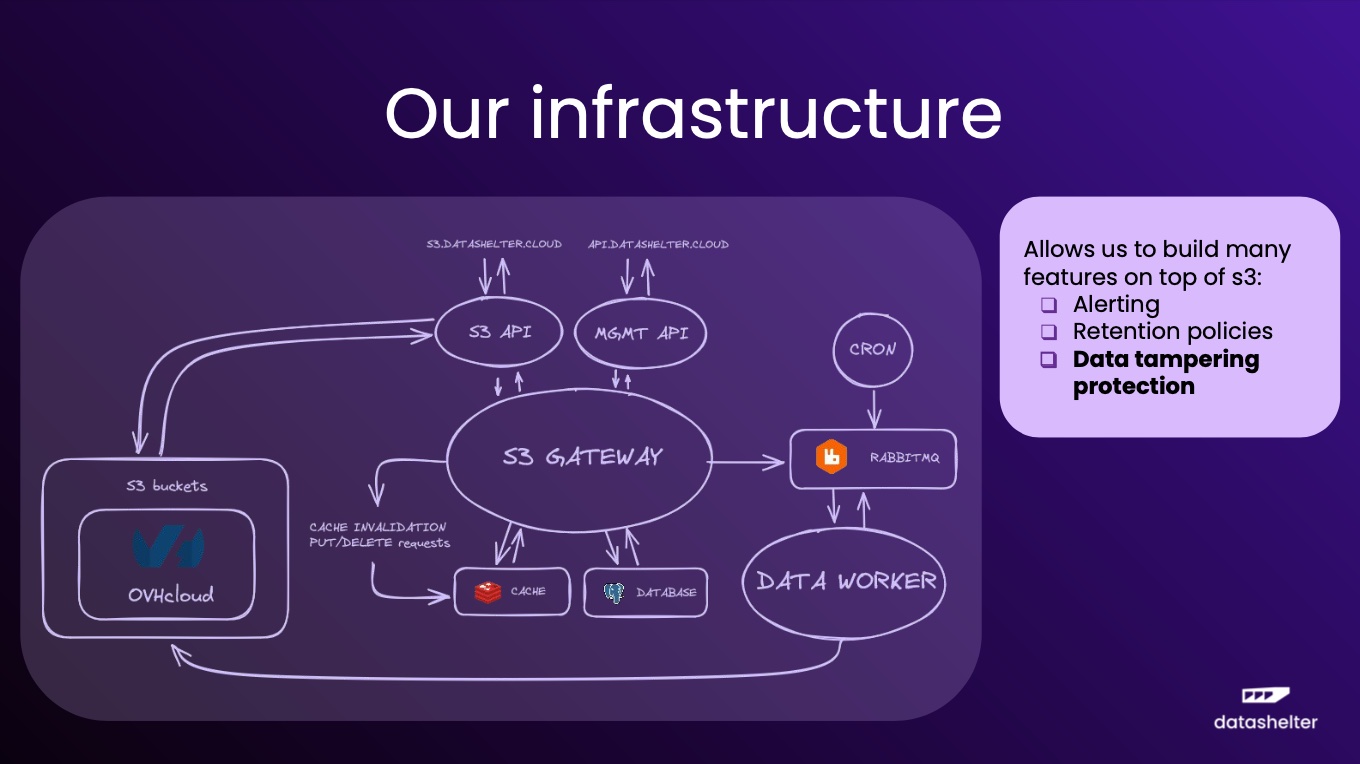
Datashelter is a backup automation tool, written in Go, that protect files and databases such as MySQL, PostgreSQL and MongoDB. The storage space is included, leveraging the S3 API and today backup images are stored on the OVHcloud infrastructure. In terms of features, it provides encryption, compression, de-dupe and incremental backups and doesn’t rely on any server or external schedule as everything is controlled by client software. In other words, there is no server in the architecture and operates as a push-only model. The solution is multi-tenant by design as each customer owns a dedicated bucket, not accessible or visible by other running clients. There is no need of SSH connection and no firewall authorization is required. It is a very light model and really secured as all data escaping the client is encrypted. It costs €5/TB/month and €2/server/month with 1TB included.
The team plans to add Kubernetes support, Windows compatibility, serverless and will accept also customers’ own S3 storage.
The company belongs to the OVHcloud Startup Program and is looking for reseller and integrators.
EU eArchiving Initiative
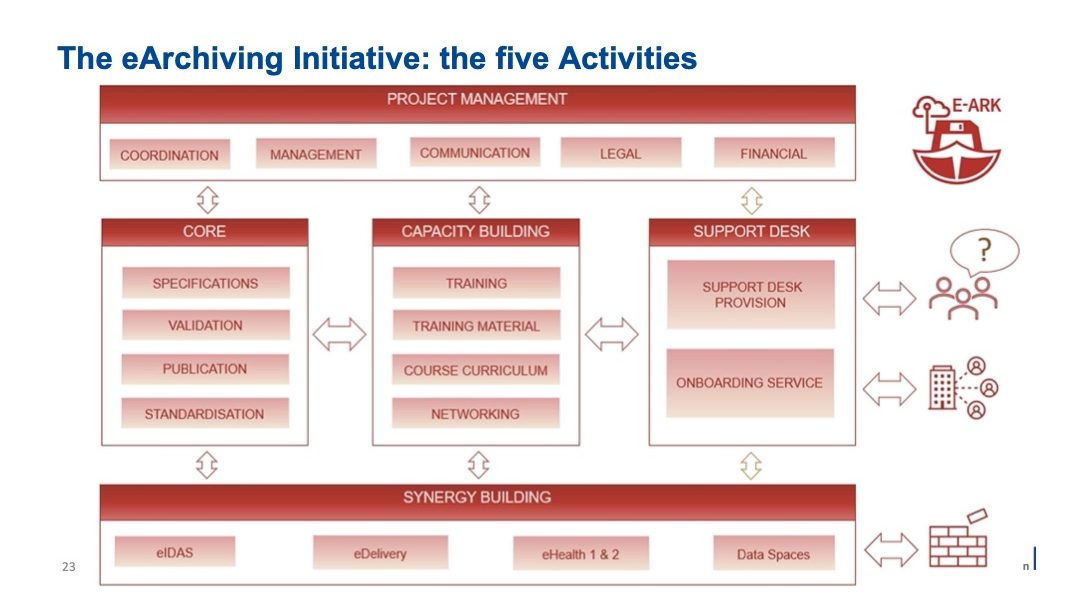
The European Union has jumped into the game with an official eArchiving initiative to harmonize practices and recommend standards and processes in the domain. It is also a fundamental project for data sharing capability between countries and associated administration and other entities. It means interoperability is a key aspect of the project. The initiative introduces the notion of Data Spaces to carefully align the need, the recommendation and solutions with each vertical sectors or industries and provide ecosystem and common services layers.
The eArchiving initiative is an official Digital Europe Program supported by DG CNECT and E-ARK Consortium and started almost 2 years ago October 1st, 2022. Each european union member is invited to participate especially in the E-ARK consortium. Again the goal is interoperability, openness and transparency, sustainability and legal compliance to reuse and share information over the long term, what is the essence of data archiving with here a supra country dimension.
E-ARK participates in the specifications across sectors, domains and countries wishing to push it as a de-facto standard. The model relies on the open archival information system reference model or ISO 14721 and targets 5 properties model: content, context, rendering, structure and behavior. This initiative is a must for Europe and at the same time it is very confidential so the need for such project to increase its visibility and participate to this kind of events. The project is well developed and users and other potential participants can navigate from this web page to dig and learn about the initiative.
So far 37 different projects reuse eArchiving components, 6 are committed to reuse them and 21 are committed to analyze them illustrating a real dynamism. Of course, users expect that this independent legal project will find some synergies with vendors’ solutions.
Hopsworks
Data integration appeared to be mandatory especially as AI popup everywhere. Founded in 2018 with €12.25 million in 3 fundings rounds, the Swedish company Hopsworks develops an AI lakehouse to integrate big data, analytics and other ML to boost data integration.
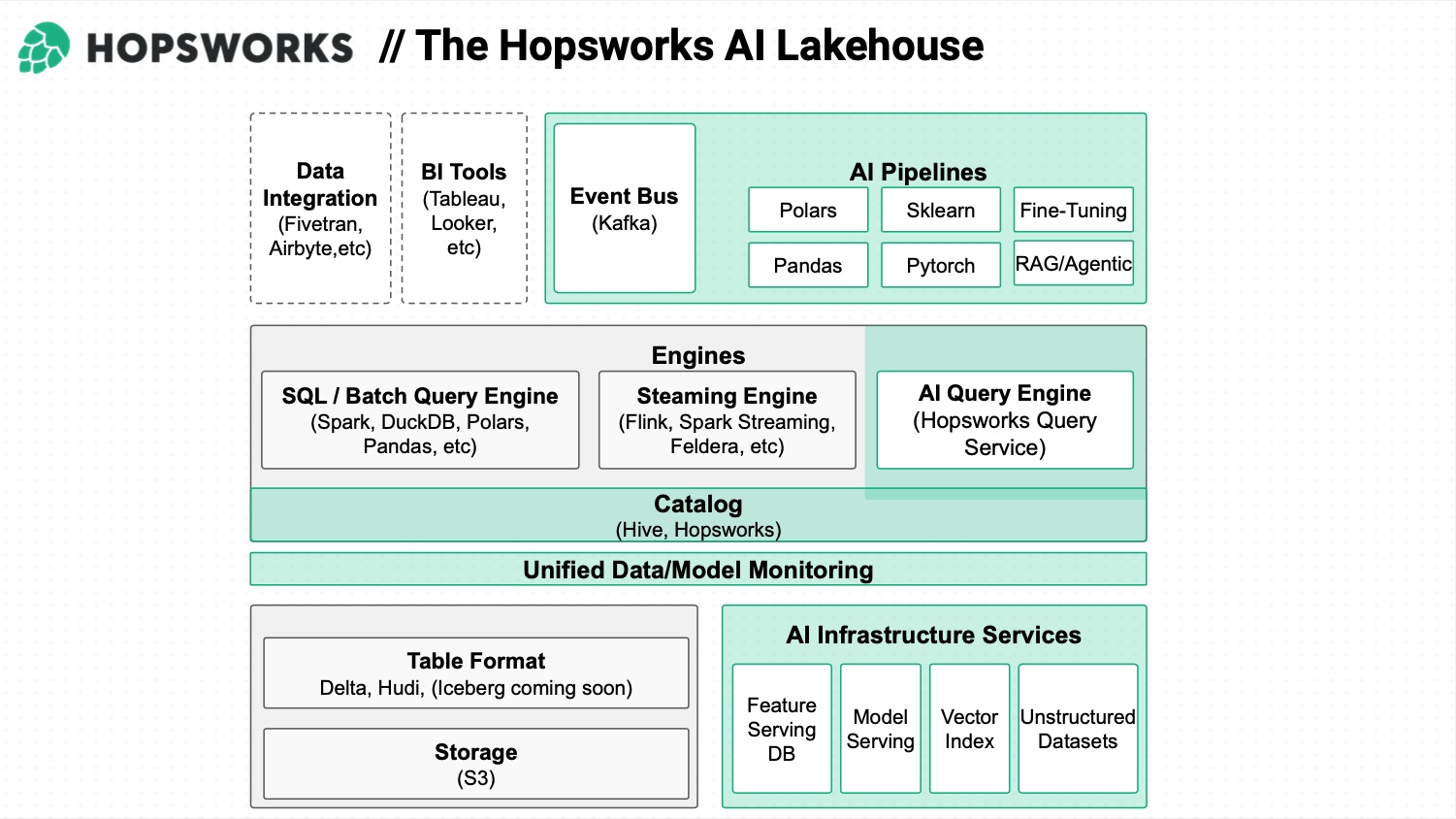
The reality is very different as data sources are disparate, teams are siloed, systems are not unified and frameworks not compatible. Hopsworks goals is to build and offer a unified data layer as query and storage layers are decoupled. Lakehouse and MLOps Platforms are disconnected meaning that data is not able to be transferred, visible from the other part and unable to be queried with consistency.
The product is already adopted by various users of any size in different verticals and industries. It is available in 3 flavors: open source as a self service version, pretty limited without SLA but good enough to assess the solution and wish to extend to other editions, serverless for a version managed by Hopsworks with limited SLA and enterprise, the full edition, delivering high SLAs and integration capabilities.
In terms of partnerships, the firm leverages Intel, AMD, Nvidia and Supermicro plus Confluent, Neo4j and Oracle and OVHcloud for the cloud platform. The solution is promoted as subscription for cloud or on-premises.
In addition to the platform, the team has developed HopsFS, a file system service built to run on S3 distributed across multiple availability regions, that is Posix compliant and compatible with the HDFS API. The result is 100x the performance of S3 for file move/rename operations and 3.4x the read throughput of S3 (EMRFS) for the DFSIO benchmark. It is interesting to see some similarities between file systems and databases technologies impacted and challenged by S3 and more globally object storage.
The firm has lot of ambitions and expect to really take-off within this AI new wave and data integration expertise.
MooseFS
Distributed file system is a hot market segment especially in the open source domain. We easily count 10+ solutions in the last 2 decades. One of the key trigger was the famous Google file system paper published in 2003 that invited several pioneers to initiate some projects. One of these is MooseFS controlled by a polish company.
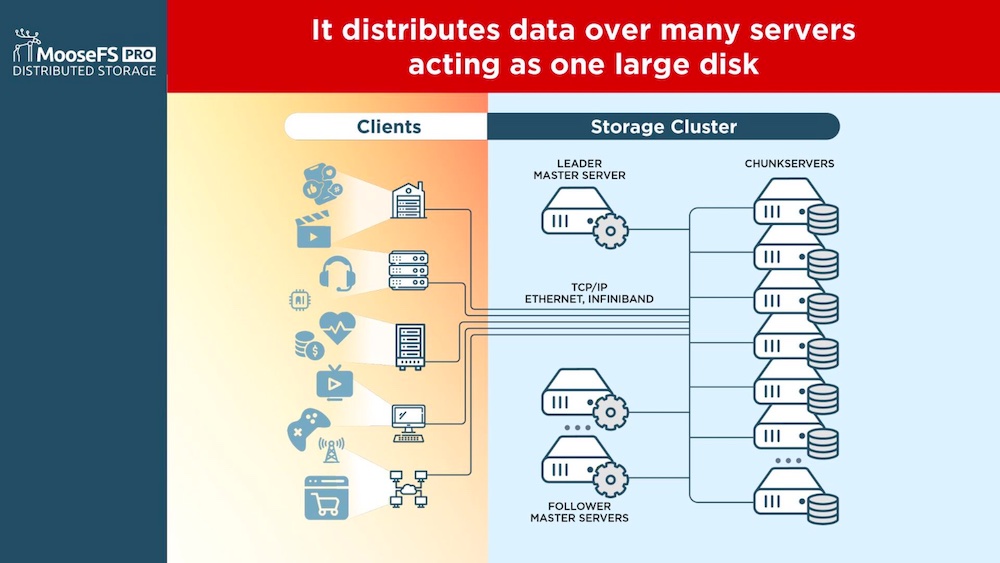
MooseFS is parallel file system that relies on 3 key elements: clients with a small piece of software that exposes data via a Posix interface or NFS, SMB and even S3. The team also adds a block interface at that level. The second element is represented by metadata servers and one of these is the leader coupled with several followers and the last layer is the data storage entities instantiated by chunk servers.
Clients play a key role as they’re responsible to stripe data and send the stream to one or several chunk servers following the exchange about location with the metadata server leader. Below 64MB, only data chunk is sent to one server and above, each 64MB is sent to a different chunk server, all operating in parallel. The idea is to send and write client data to servers the most rapidly. As soon as the data is received, a replication task is started across data servers to provide the first minimal protection. As erasure coding is available in 8+1 in the community edition and 8+2 in the pro edition, this schema is launched in the background after the full replication is finished. Other features are given such as snapshots, tiering and such client models offer the capability to run jobs directly on clients.
The product is hardware agnostic and is a good example of a SDS approach. Clients can run Linux, MacOS and Windows, servers in their metadata and data flavors, run Linux.
The MooseFS team picked the tour to launch v4.0 open source release available on GitHub.
The company is profitable and generates revenue with support of course and pro licenses that extend the community edition. The pricing relies on total raw disk space and the management team has chosen to not offer subscription for the pro version.
ZeroPoint Technologies
Founded in 2016 as a spinout from Chalmers University, the Swedish company raised so far $16.3 million in 10 rounds. The entity was founded by Dr Angelos Arelakis, CTO, and professor Per Stenstrom, CSO, after a natural incubation period at the university.
The team targets the 3 famous pains regarding memory performance: it has become a real performance bottleneck, size and management is inefficient and finally it continues to be very expensive. And AI has accelerated the first challenge as the domain requires much memory than other domains.
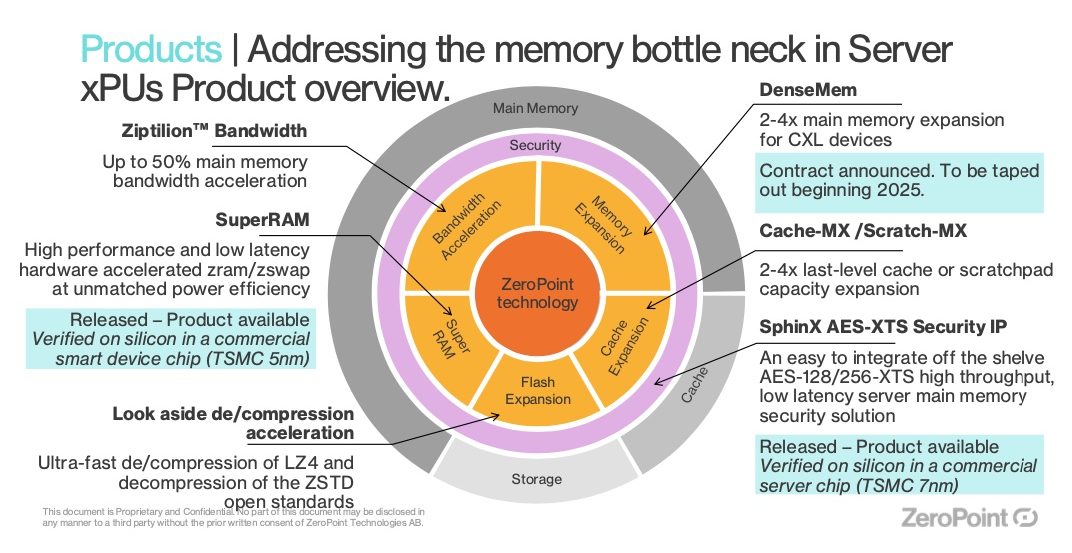
ZeroPoint has developed a pretty unique memory compression technology that boosts performance as the memory utilization increases, keeps only relevant data in place and finally optimizes the TCO and its associated TCCO – total cost of carbon ownership.
The development relies on advanced algorithms and delivers inline compression at 2-4x ratio with cache line granularity coupled with a specific OS agnostic memory management driver. But one of the beauty of this solution is the almost absence of latency with a factor of 1000 between approaches. The other gain is on the performance per watt with 50% higher ratio. It was demonstrated on 5nm TSMC foundation, adopted by 1 CXL vendor and listed on 1 ARM partner catalog.
ZeroPoint has developed a real product line addressing these challenges at different places: on-chip memory, off-chip memory and storage.
This is recognized as a must by hyperscalers and even OCP has published a paper about this challenge and how to address it.
In terms of business it appears to be a long run with a 24-36 months sales cycle that requires other funding rounds to boost valuation, delay acquisition and for sure accelerate barriers to entry for others.
With 70 patents filled, I’m afraid that this technology will be so attractive for processors and memory maker but also CXL developers and for sure hyperscalers that ZeroPoint will probably land somewhere…






 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

