







StorPool Builds Storage Platform Block by Block
Latest iteration of software introduces features, including near-zero performance impact Erasure Coding that improves data efficiency and expanded cloud management platform integrations.
This is a Press Release edited by StorageNewsletter.com on October 17, 2023 at 2:02 pmStorPool Storage released the 21st version of its primary storage platform, which introduces new capabilities and features including fast and efficient Erasure Coding, cloud management integration improvements and enhanced data efficiency – some of which have never been previously available from any block storage vendor.
The platform transforms standard hardware into fast, highly available and scalable storage systems at up to half the hardware cost per usable terabyte. With this, organizations streamline their entire IT operations through the implementation of a single storage system to serve all their workloads and connect all their cloud platforms through a hands-off approach to storage infrastructure.
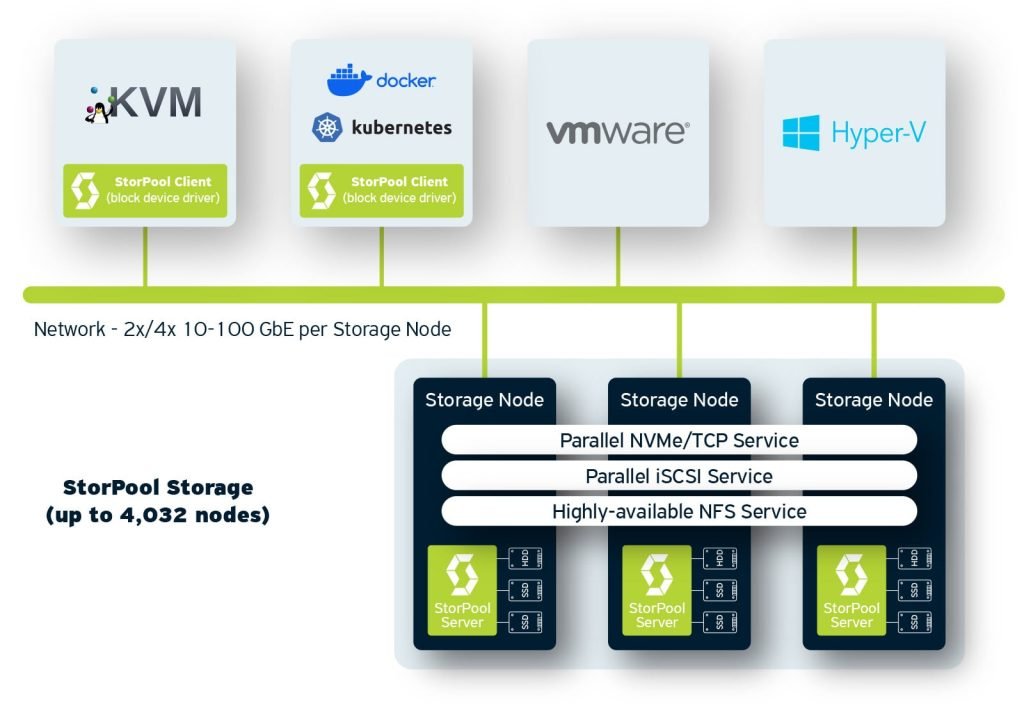 With this new release, the companyintroduces major improvements to its data protection, efficiency, availability, and compatibility expertise. Chief among the highlights of v21’s improvements is the implementation of Erasure Coding that protects vs. drive failure or corruption with virtually no impact on read/write performance.
With this new release, the companyintroduces major improvements to its data protection, efficiency, availability, and compatibility expertise. Chief among the highlights of v21’s improvements is the implementation of Erasure Coding that protects vs. drive failure or corruption with virtually no impact on read/write performance.
When deployed on at least 5 all-NVMe storage servers, firm’s implementation of Erasure Coding provides 4 key capabilities:
- Cross-Node Data Protection – information is protected across servers with 2 parity objects so that any 2 servers can fail and data remains safe and accessible.
- Per-Volume Policy Management – volumes can be protected with triple replication or Erasure Coding, with per-volume live conversion between data protection schemes.
- Delayed Batch-Encoding – incoming data is initially written with 3 copies and later encoded in bulk to reduce data processing overhead and minimized impact on latency for user I/O operations.
- Always-On Operations – up to 2 storage nodes can be rebooted or brought down for maintenance while the entire storage system remains running with all data remaining available.
“Delivering high-performance erasure coding on scale-out primary block storage that protects vs. multiple concurrent drive and node failures is genius,” said Marc Staimer, president, Dragon Slayer Consulting. “It makes multiple concurrent drive or node failures a ‘non-event’ with nominal to no performance impact while accelerating data rebuilds – not drive rebuilds – by orders of magnitude.”

With the new Erasure Coding capabilities provided in this offering, customers can now select a more granular data protection scheme for each workload, right-sizing the data footprint for each individual use case. In large-scale deployments, customers can perform cross-rack Erasure Coding to enable their storage systems to benefit from data efficiency gains while simultaneously ensuring the survival of failure from up to 2 racks.
Other major enhancements deployed as part of v21 release include:
- Improved iSCSI Scalability – allowing customers to export up to 1,000 iSCSI targets per node, especially useful for large-scale deployments.
- CloudStack Plug-In Improvements – introduces support for CloudStack’s volume encryption and partial zone-wide storage that enables easy live migration between compute hosts.
- OpenNebula Add-On Improvements – now supports multi-cluster deployments where multiple firm’s sub-clusters behave as a single large-scale primary storage system with a unified global namespace.
- OpenStack Cinder Driver Improvements – enabled easy deployment and management of company’s Storage clusters backing Canonical Charmed OpenStack and OpenStack instances managed with kolla-ansible.
- Integration with Proxmox Virtual Environment – with the integration, any company utilizing Proxmox VE can benefit from end-to-end automation, allowing its IT teams to focus on strategic projects rather than managing individual IT stack components.
- Additional Hardware and Software Compatibility – increased the number of validated hardware and operating systems resulting in easier deployment of StorPool Storage in customers’ preferred environments.
Additionally, the company’s VolumeCare(c) backup and DR function is now installed on each management node in the cluster for improved business continuity. It is always running in each of the management nodes with only the instance on the active management node actively executing snapshot operations. Another connected enhancement provides performance improvements for large backup clusters.
“The one thing that always impresses me about StorPool Storage is their commitment to constantly making it an even better solution rather than resting on their laurels in having built a superior primary storage solution in the first place,” said Kevin Schouwenaar, technical director at Hosted.nl. “Just the addition of Erasure Coding provides us the protection we need as data sets continue to grow without the overhead or limitations of triple replication or RAID-1.”
StorPool Storage is designed for workloads that demand utmost reliability and low latency. It enables deploying high-performance, linearly scalable primary storage systems on industry standard hardware to serve large-scale clouds’ storage and data management needs. With the vendor, businesses streamline their IT operations by connecting a single storage system to all their cloud platforms while benefiting from its utterly hands-off approach to storage infrastructure. The firm’s team designs, deploys, tunes, monitors, and maintains each storage system so that end-users experience fast and reliable services while its customers’ tech teams dedicate their time to the projects that aim to grow their business.
“Since developing our storage platform from the ground up in the years following 2012, we continue to push the limits of what’s possible in storage with each new version of StorPool Storage,” said Boyan Ivanov, CEO, StorPool Storage. “After all these years, the core capabilities remain the same – a software that is fast and efficient, simpler, and smarter, and at a lower cost so that our customers retain better margins. With v21, we once again push the limits of what’s possible by delivering better data protection through Erasure Coding, improving business continuity, and ensuring compatibility with the latest technologies available. Why settle for other solutions when you can optimize your entire data center TCO with revolutionary storage built and managed for
you?”
Details about the latest improvements to data protection, availability and integration with popular cloud management platforms included with v21 is available as part of the StorPool changelog.
Comments
This Erasure Coding (EC) news represents a key milestone for StorPool as we anticipate this data protection feature for quite some time.
And it was clearly a miss if we compare with the competition and it was considered as a must have for a several years now.
Until this release the product offers only replication and will provide both protection schema - replication and EC - with the v21.
In fact, we can estimate that below a certain threshold, replication is adequate for small files and above EC is definitely the way to go. In other words, it becomes difficult to adopt replication for large scale environments as with 10PB of usable data, the configuration would consume 20PB just for protection. The v20 release announced in 2022 added NVMe, AWS and NFS front-end in addition to their classic iSCSI and own block protocol.
The engineering team has chosen a Reed-Solomon approach working across chassis but not within a chassis, there is no protection within a chassis as the protection works at the volume level. They also implement a systematic EC model and globally works as a N+2 whatever is the size of the volume and number of units, disks or SSDs.
For our readers a systematic model is when original data chunks are maintained and get coupled with parity chunks. When all data are scrambled and distributed, it is called non-systematic.
For StorPool users who already adopted their SDS, the migration from replication to EC is transparent.
A minimum of 5 nodes is necessary to enable the EC mode. When 5 nodes is used, the team recommends 2+2, for more than 7 nodes, 4 2 and above 11 nodes, 8+2. As already said, this EC model works at the volume level and of course different volumes can coexist with different EC schemas. So even with very large stripe, let say 20, 30 or even more, just 2 additional units or chunks are dedicated to parity, perhaps not enough when you reach this number. You can argue to create more volumes with less disk but in that case the hardware efficiency is not the same, the reverse is true if you consider the other dimension key, here, the hardware overhead. So why didn't they implement a +3 schema for wide volume?
For small clusters, hardware overhead is 100% for 2+2, then 50% for mid size and finally 25% for large one. For storage efficiency, it means 50%, 66% and 80% approaching the record we see elsewhere. But record is not the right term as the goal is to offer very efficient protection. N+3 when N is 20 project 15% of overhead and almost 87% and for N equals 30 just 10% and 90% respectively.
The other interesting aspect about StorPool is its compatibility and support of VMware, Kubernetes, OpenStack, CloudStack, OpenNebula, Proxmox or OnApp for public and private cloud.
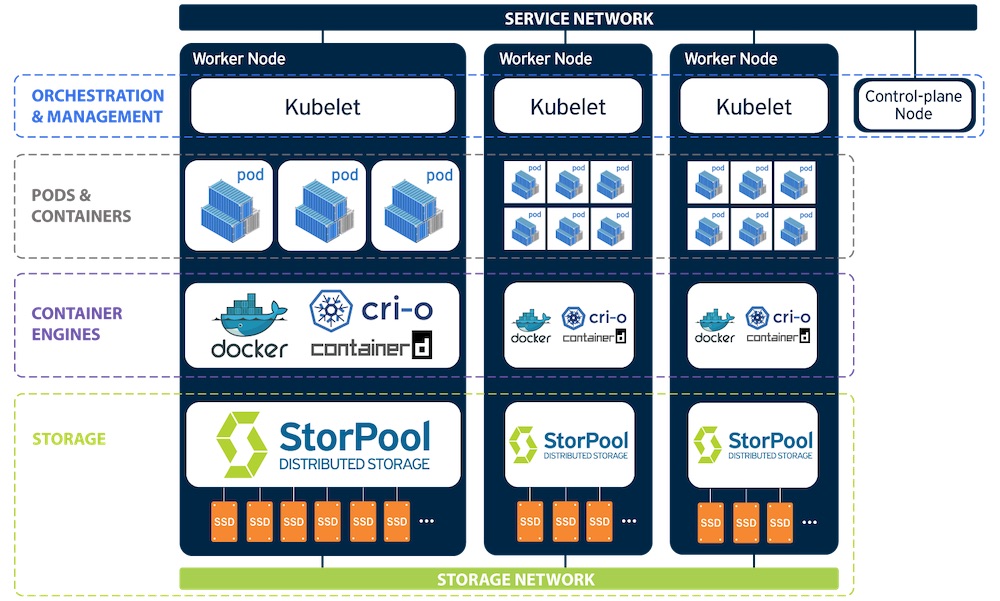
Covering the company for almost 10 years, we understand that they reach a profitability state but they still suffer to be more visible and considered for large deals overseas even if they won some. We realize that a refresh on their go-to-market is a must to sustain some sort of growth in a very dynamic and competitive landscape.
They probably need to raise money but again Europeans have some difficulties to accept dilution and loss of control.
We know the rest of the story, this kind of companies stay behind due to their profile not the technology. So I imagine a strategy around picking 1 or 2 OEMs to promote and sell the solution, some vendors are open to it but again it will take times.
In term of block storage competition, we have seen various trends and dynamic on the market beyond gorillas presence. We all remember some early SDS vendors like Datera, ScaleIO or even before Letfhand Networks. Then E8, Mangstor morphed into Exten, Apeiron and more recently Excelero… who get swallowed or disappeared. Solidfire belongs to this group and got acquired by NetApp, Vexata and Pavilion Data hit a wall same thing for ioFabric, OpenvStorage or Coho Data. Kaminario transformed into Silk and even Kioxia has stopped Kumoscale. So some negative trajectories and some interesting new or recent ones with Lightbits Labs, Linbit, Nyriad, Ceph, StorMagic, StarWind, NGX, Volumez and Simplyblock, we can even mention FlashGrid and of course DataCore, with an installed of 10,000+ SANsymphony sites.
One key aspect with SDS globally is that it finally gives the feeling of reducing the value a solution can offer and make all vendors and solutions the same. They run on the same standard hardware, with same OS, network, disk and provide most of the time same feature. And they battle on price not on differentiators. They all swim in a red ocean.
So clearly there is a market no doubt about this, but who are the players who really count in it? As usual a large customer buys from a large vendor, a small user is flattered to be considered by a large vendor and its partner network. So at the end, the only moment when a large user buys from a small vendor is when that user finds some innovative aspects in this solution. So again a perfect illustration to the innovation race but keep in mind that "me too" strategy just fills gaps and don't create advanced approaches…






 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

