







Considerations on Recent OVHcloud Disaster
It invites us to review approaches and processes on BC/DR effective solutions.
By Philippe Nicolas | March 23, 2021 at 2:33 pmOVHcloud recent outage, we should say disaster, at their Strasbourg site located in North East of France, reminds our dependency to the cloud and we already read on different places on-premises defenders or competitors arguing different perspectives.
First, let’s summarize the profile of OVHcloud. Founded in 1999 by Octave Klaba, the company was named OVH for “On Vous Héberge” that can be translates as “We Host You“, and so far for these last 20 years, it was and it is a big success with a growth.
The company raised so far €650 millions in 2 rounds (private and debt financing). The firm has recently announced its plan for IPO, scheduled pretty soon, to accelerate its expansion. OVHcloud also acquired two bargains, Exten Technologies and OpenIO, respectively in NVMe-oF and object storage categories. Both companies struggled. We imagine some plans to replace the current block storage offering and Ceph as well.
As said, OVHcloud had a serious fire on several data centers on March 10 and, as of today, the recovery and restart is still going with of course serious impacts on clients businesses. The company has published this page in French a few days ago and a more recent update here that summarize in details all services impacted (HA-NAS based on ZFS, kimsufi, datastore, managed Veeam backup, VPS, Ceph block storage…). HA-NAS promotes 99,99% of availability of the service page which means 52 minutes of downtime per year. Several services are recoverable without data loss which is good but several others are unrecoverable. Veeam service was also impacted as images were stored in the same DC, it would have been easy to copy and stored them elsewhere. And we even find a page promoting Zerto but we don’t know if lots of users adopt it as this solution can prevent such disaster impact. You can also check this page to see the list of active servers on all data centers and follow the recovery phase.
Damages were impressive and invite us to wonder how such disaster can occurred but above all how business can continue even during such trouble. The web site of StorageNewsLetter.com is stored on OVH but didn’t encounter any problem as it is hosted in Canada.
It gives the opportunity to learn lessons again – and it seems that users and providers forget them or refuse to implement solutions – but also the wish to refresh our readers with some approaches to prevent impact following such disasters. Globally things to be done are the responsibility of users and providers. It’s too easy and short to say, providers are responsible and the reverse is true as well.
The cloud is not magic and should not change how users consider and use cloud services. Of course, it illustrates that within cloud providers, infrastructure and associated hidden operations services are not equal at all.
In term of consequences, on the customer side, we heard that more than 3 millions websites and associated applications were impacted, stopped, delayed and many continue of them just disappeared. On the provider side, of course, its image is seriously impacted and creates some doubt of its capabilities to offer a resilient service. It reminds what happened almost 3 years ago at another OVHcloud site following a Dell EMC storage array issue. But the French company is not alone and we all remember Dropbox, Google, AWS or Azure to name a few. But it’s a reality, the complex and comprehensive services are fragile and maintaining a service even in a degradation is a mission.
As a general comment, people don’t judge things when everything is up and running but more when things are going worse and bad. In sport, we say how to win when your team doesn’t play well. And we all remember the famous words “failure is not an option” during the Apollo mission I think. On the other hand, at scale, failure is a common aspect occurring everyday at different levels. And users expect these to be transparent on services they use.
First comment on the nature of the provider, is it a SaaS, a PaaS or a IaaS? If we consider an IaaS, clearly developers that pick this provider must implement their own prevention and resiliency model. For SaaS, this is clearly different as subscribers expect a more global and transparent model. In other words, for IaaS the responsibility is more on the implementers that use providers’ infrastructure to build and offer its services. For SaaS, it is clearly on the vendors side, how can Salesforce offer its service without some resiliency? Clearly it’s a huge problem and users must pay better attention to that as they discover, sometimes later, that they need to consider third party software to protect their data stored within Salesforce cloud perimeter. This is just incredible for a SaaS, again we consider this normal for IaaS.
These rapid elements invite us to reintroduce the concept of RPO and RTO for both applications and data. What is important is users’ perception meaning that the time of availability of a service is not a system perspective but a user one. A database can be restarted, seems to be available because you see processes running… but for any reasons it refuses users’ transactions so the service is categorized as unavailable.
The image below with RPO and RTO illustrates the mapping providers and admin/developers must do to access what is acceptable both in term of data you can loose, you can reenter, downtime you can accept…
Imagine 3 areas:
- First example, you have source code servers with hundreds of developers, you don’t wish to loose any lines of code but you have time to restart the service. It means short RPO, almost CDP or near-CDP, with a few days of RTO. This is acceptable as there is no revenue associated to the source code servers.
- Second example, you have static web sites, and for this usage you can tolerate flexible RPO but with very short RTO as these sites represent the image of the company. You need to restore the service as soon as you detect the failure.
- Last example of a commercial site with business transactions. Obviously as revenue is exposed via the platform, you wish short RPO and short RTO, let’s say transparent failures that finally never impact the business.
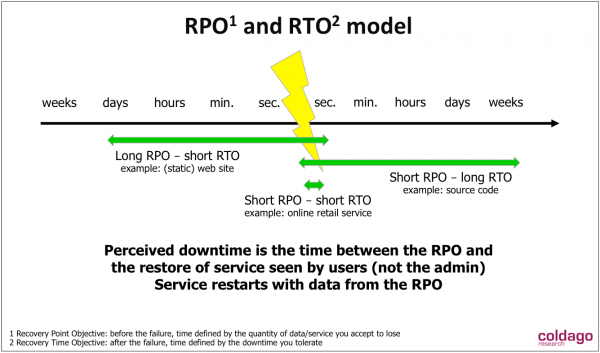
This RTO dimension includes the need to restart a business super fast or with a certain time. It is translated to business continuity or data protection and even disaster recovery plans. We see design of resiliency services with CDP, snapshot, mirroring, RAID, erasure coding, dispersed or geo distributed coupled with HA clusters within on DC or across DCs and of course backup sometimes forgotten by users even here. On the image above, we can imagine a backup policy for the 1st example, it could be also replication but both have low frequency. For the 2nd example, the data capture is key as soon as it changes happen so we see here things like snapshot, CDP associated with remote copy (asynchronous could be enough). Data are secured, durability is guaranteed and you have time to recover. The last example is demanding for both before and after the failure, so you need to consider a CDP-like approach, with synchronous mirroring, and some capability to restart or continue processing at a different place with clustering technologies. Here the failure detection is key, the HA engine must take the right decision and then execute that decision to maintain the activity. All of these arrive with a cost that legitimates the mapping with this model for instance.
Let make thing progressive, the first key element to consider is related to the service you wish to protect: Is it an application, is it an issue with data, is it both?
The fundamental element is to separate things, the more you can decorrelate or decouple the more you will isolate failure and avoid propagation and global failure impact. In other words, think modular elements you can run independently, in different places, and avoid any convergence approaches… that finally give you the opposite. This is one of the reasons disaggregated infrastructures are adopted by hyperscalers. The level of protection is fundamental, what can you tolerate, can you lose a process, a service, a node, a cluster, a site… and even if you have safe elements, one element in the chain can make the service down.
Obviously, this disaster demonstrates that applications and data are critical to sustain the business. Make applications highly available is useless if these ones don’t have any data to process and serve. In the same way data without any applications could appear to be useless, it’s true for immediate needs but their durability is paramount. Again except if misinformation was shared, people who didn’t implement relevant prevention and protection services have accepted the risk to lose data, to have a business stopped and be seriously impacted.
This idea of separation is associated with a redundancy aspect, it’s true for applications, multiple instances, all active or just a few one and others dormant, and also for data. For this, it is important to consider production and protection data, have multiple instances of them and of course, this mandatory residing at different sites. Having all tapes and disk images on the same DC under fire doesn’t help. And users can argue: “I use snapshots, multiple versions of them, copy them of different servers, plus high-end disk arrays with RAID and replication, then local cluster software for HA and finally use strong backup processes. But you’re right even with all these mechanisms I keep all of these in the same DC and the risk exposure is high.”
This example is pretty common representing an incomplete approach and the multi-site is completely absent. Basically why applications are running on the same site with the storage, it could be related to some constraints, why applications don’t send similar transactions to multiple storage in different sites. Remember what an airplane is doing, 3 computers running same programs in different languages, OSs, all in parallel… with checkpoints, rendez-vous… to eliminate doubt, surprises and failure especially at 36,000 feet. Here we understand it could be extreme and it is considered as fault tolerant but some businesses require this.
Again it’s a question of price for both providers and developers. A reasonable implementation should be to deploy different tier of applications on different zones or regions, depending of the terminology use, and again consider various datastore in different places. At each layer horizontally, redundancy is paramount.
We all agree on the necessity to adopt multi-cloud to avoid vendor locking, on-premises and in the cloud, and this idea is strengthened by such data centers failures. It could be mutli-zone, area or region but please don’t put everything in the same DC, this is both stupid and prove a lack of maturity that should invite the user to doubt on services. So we invite users to always ask how things are protected? How services are maintained? Did BC and DR plans tested and how often…? and if answers are not enough, avoid providers with limited solutions and lack of real tested processes and procedures.
If we just consider backup, 3-2-1 model is a must and we don’t know why it was not the case. 3 copies, 2 formats and 1 copy on different sites or a degraded model with 2 copies in 1 format but each copy stored at different sites. Again the minimum is to have multiple copies, multiple versions and have enough retention time to have options. And don’t forget to test online or offline copies often to validate them but also to tune and validate as well continuity and recovery processes. This dramatic example clearly shows that tests were not made, this kind of failure ignored… How could we imagine the opposite except if users accept the impact.
And by the way, some other cloud vendors just added promotion and we saw some popup windows after you login on some of these that invite the user to consider to backup his environment. At least this new disaster can serve as strong reminder for all of us. Always backup and make copies of your data and keep them in a safe place, this is a minimum…





 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter
