







Cloudera Enterprise 5.10 With Apache Kudu OSS Storage Engine for Analytics on Fast Moving Data
Simplifies path to real-time analytics, allowing users to act quickly on data as-it-happens to make business decisions.
This is a Press Release edited by StorageNewsletter.com on February 8, 2017 at 2:33 pmCloudera, Inc. announced that Apache Kudu, an open source software (OSS) storage engine for fast analytics on fast moving data, is shipping as a available component within Cloudera Enterprise 5.10.
Cloudera Enterprise architecture
Click to enlarge
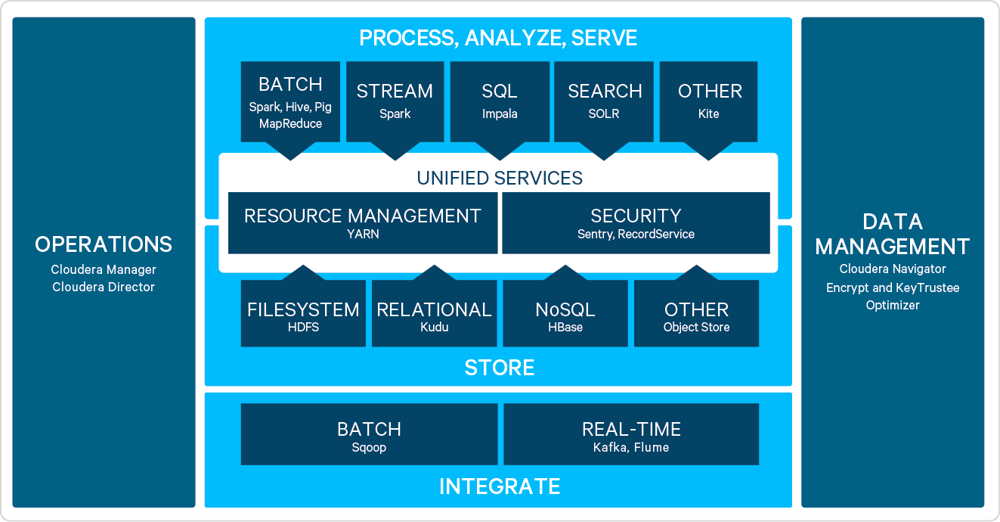
Kudu simplifies the path to real-time analytics, allowing users to act quickly on data as-it-happens to make better business decisions.
“Real-time data analysis has been a challenge for enterprises because it required a complex lambda architecture to merge together real-time stream processing and batch analytics. Kudu dramatically eases that architecture with a single storage engine that addresses both needs,” said Charles Zedlewski, SVP, products, Cloudera. “The high-demand workloads in place today, which include a growing number of new machine-learning models, can identify cybersecurity threats, predict maintenance issues in the industrial IoT, and bring much more accuracy to all types of online reporting.“
Kudu was designed to take advantage of innovation in the hardware landscape, which has seen solid state storage, memory, and RAM become more affordable. As a standalone storage engine, It has already proven itself for mission-critical production use in clusters with hundreds of nodes handling many millions of inserts per second. Kudu is purpose-built to enable use cases that require fast, large-scale analytic scans while supporting rapidly updating data – necessary for handling time series data, machine data analytics, online reporting, or other analytic or operational workload needs.
“Apache Kudu is a prime example of how the Apache Hadoop platform is evolving from a sharply defined set of Apache projects to a mixing and matching of open source and proprietary technologies that form, in essence, a big data operating environment,” said Tony Baer, principal analyst, Ovum. “Kudu bypasses the hurdles associated with complex lambda architectures to address use cases involving fast-changing data, where the ability to rapidly modify and update the database are critical.“
Beta programs for select company’s customers, directly and through partners, have driven Kudu into critical production environments. Further adoption is anticipated among firm’s customer base to address the ever-increasing number of use cases that require real-time analytics.
“Achieving compliance and operational reporting alongside analytical success requires both the ability to process large amounts of data to find trends, and to detect and respond to anomalies quickly,” said Michael Reed, director, enterprise information management, Meridian Health. “We’re excited about the potential of Kudu to allow us to do analytical and real-time operations in a single place to help us to simplify the systems that we build.“
Cloudera Navigator
Click to enlarge
Addition to Kudu, Cloudera 5.10 (and release of Director 2.3) continues to enhance enterprise-grade capabilities for cloud deployments and improve cost-efficiencies in these environments.
Capabilities include:
-
Reduced operating costs for batch processing on transient workloads with improved performance of Apache Hive on Amazon S3
-
More comprehensive auditing and lineage in the cloud with single-cluster Cloudera Navigator support for Amazon S3
-
Reduced time to deploy initial use case with faster first run deployments across cloud environments
In September of 2015, the company announced the public beta release of Apache Kudu, and two months later, the firm donated Kudu to the Apache Software Foundation (ASF) to open it to the broader development community – garnering contributions from engineers at State Farm, Xiaomi, Intel Corp., and others. Kudu is available and shipping as a standard component of Cloudera Enterprise, giving customers a set of storage engines – NoSQL, HDFS, object store, and relational – to meet the specific needs of their use case.
“Apache Kudu represents a major advance in the field of open source database technology, enabling real-time data analytics in ways that were previously very challenging to implement. We see a wide array of uses cases for Kudu, particularly in the InsurTech sector, and expect it to have a positive impact on many of our clients and projects in the coming years,” said Cory Isaacson, executive chairma, Agil Data (SI).
“We’re thrilled to integrate Apache Kudu with Arcadia Enterprise as it provides a real-time and responsive storage engine for data-centric business applications. As an application developer it’s great to have a clean API that we can use through Apache Impala, Apache Spark or directly within Arcadia Enterprise. With Kudu, we have finally come to a point where Hadoop goes beyond ingesting and analyzing data to become the de facto place where Arcadia can generate and update data without the need for any data movement,” said Shant Hovsepian, co-founder and CTO, Arcadia Data, Inc.
“The main goal of a recent credit card processing project at Avalon was to re-architect our client’s traditional batch-oriented processing system to improve agility and add real-time fraud detection alerts alongside near real-time executive dashboards. Using Kudu and Impala, we were able to meet the sub-two-second response time required for queries from the new system. Achieving this with the existing EDW would have been cost prohibitive compared to leveraging Cloudera, and Kudu helped us meet our most critical latency requirement,” said Tom Reidy, CEO, Avalon Consulting, LLC.
“As Capgemini’s clients are maturing in their usage of big data, analytics and data science, the need for more real-time analytics workloads on big and fast data, including IoT and streaming data, has become a more and more central topic. The GA of Kudu is a great step towards allowing our clients to build even more critical, insights-centric processes on top of their business analytics platform, which will accelerate their Digital Transformation journey,” said Anne-Laure Thieullent, VP, global big data solutions, insights and data, Capgemini Service SAS.
“RCG Global Services sees Kudu as an important advance in storage for big data. It provides low-latency and high-performance for reading and writing data on Cloudera clusters to meet the needs of demanding applications, including real-time analytics. At RCG Global Services, we have incorporated Kudu into all of our Cloudera certified RCG|enableindustry solutions for banking, healthcare, hospitality, insurance, and retail to take advantage of these features,” said Rick Skriletz, global managing principal, RCG Global Services, Inc.
“Apache Kudu is outstanding advanced columnar storage, which SoftServe trusts to keep data centralized, accessible, and secure. As part of a recent payment processing project involving a ‘Big Four’ professional services firm, SoftServe developers chose Kudu for its ability to support massive data sets while providing transactional consistency. Kudu was the only tool that had both characteristics and passed comprehensive performance and reliability tests, enabling us to deliver an innovative solution that supported our client’s business goals,” said Todd Lenox, VP, digital partnerships, Softserve, Inc.
“Incorporating Apache Kudu into CDH will greatly simplify execution of the mixed workloads our customers increasingly utilize once they migrate their enterprise data warehouse and real-time streams to Hadoop. The Cloudera-certified StreamSets Data Collector natively supports Kudu as a plug-and-play dataflow destination, and StreamSets Dataflow Performance Manager helps assure the continuous availability and accuracy of the data flowing into Kudu,” said Arvind Prabhakar, CTO, Streamsets, Inc.
“Kudu provides us a quantum leap in our client engagements requiring a fast data services layer that can effortlessly handle the high velocity of data in modern digital systems. For example, in the modern high performance IoT system we are designing for our customers, the combination of Apache Spark with Apache Kudu is essential to meet system requirements. A key added benefit for us is that there is no need to retrain our developers who are already skilled in the Apache Hadoop HDFS technology stack in order to effectively use Apache Kudu. We are glad to note the GA of Apache Kudu and expect to use it widely in our client engagements,” said Dr. Satya, VP, digital business, TCS (Tata Consultancy Services Limited).
“The GA of Kudu within Cloudera Enterprise is an important milestone on the path to streaming analytics. Zoomdata saw the value of Kudu early in its development and worked with the Cloudera engineering team to develop a set of big data analytic capabilities that leverage Kudu. We’re now in a position deliver even more value to Cloudera and Zoomdata’s joint customers through the ability to run visual analytic queries in real time,” said Ruhollah Farchtchi, CTO, Zoomdata, Inc.
Resources for Apache Kudu
Start contributing.
Register for webinar series
Engineering and VISION blogs
Resources for Cloudera 5.10
Cloudera Engineering Blog
Download Cloudera 5.10
Release Notes






 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

