







288,076 Hard Drives Tested by Backblaze
For 2nd quarter in row, 14TB Seagate (model: ST16000NM002J) had zero failures.
This is a Press Release edited by StorageNewsletter.com on November 18, 2024 at 2:02 pm This market report, published on November 12, 2024, was written by Andy Klein, principal cloud storage storyteller, Backblaze, Inc.
This market report, published on November 12, 2024, was written by Andy Klein, principal cloud storage storyteller, Backblaze, Inc.
Backblaze Drive Stats for 3Q24
As of the end of 3Q24, Backblaze was monitoring 292,647 HDDs and SSDs in its cloud storage servers located in our data centers around the world. It removed from this analysis 4,100 boot drives, consisting of 3,344 SSDs and 756 HDDs. This leaves us with 288,547 hard drives under management to review for this report.
We’ll review the AFRs for 3Q24 and the lifetime AFRs of the qualifying drive models. Along the way, we’ll share our observations and insights on the data presented.
Hard drive failure rates for 3Q24
For our 3Q24 quarterly analysis, we remove the following from consideration: drive models which did not have at least 100 drives in service at the end of the quarter, drive models which did not accumulate 10,000 or more drive days during the quarter, and individual drives which exceeded their manufacturer’s temperature spec during their lifetime. The removed pool totalled 471 drives, leaving us with 288,076 drives grouped into 29 drive models for our 3Q24 analysis.
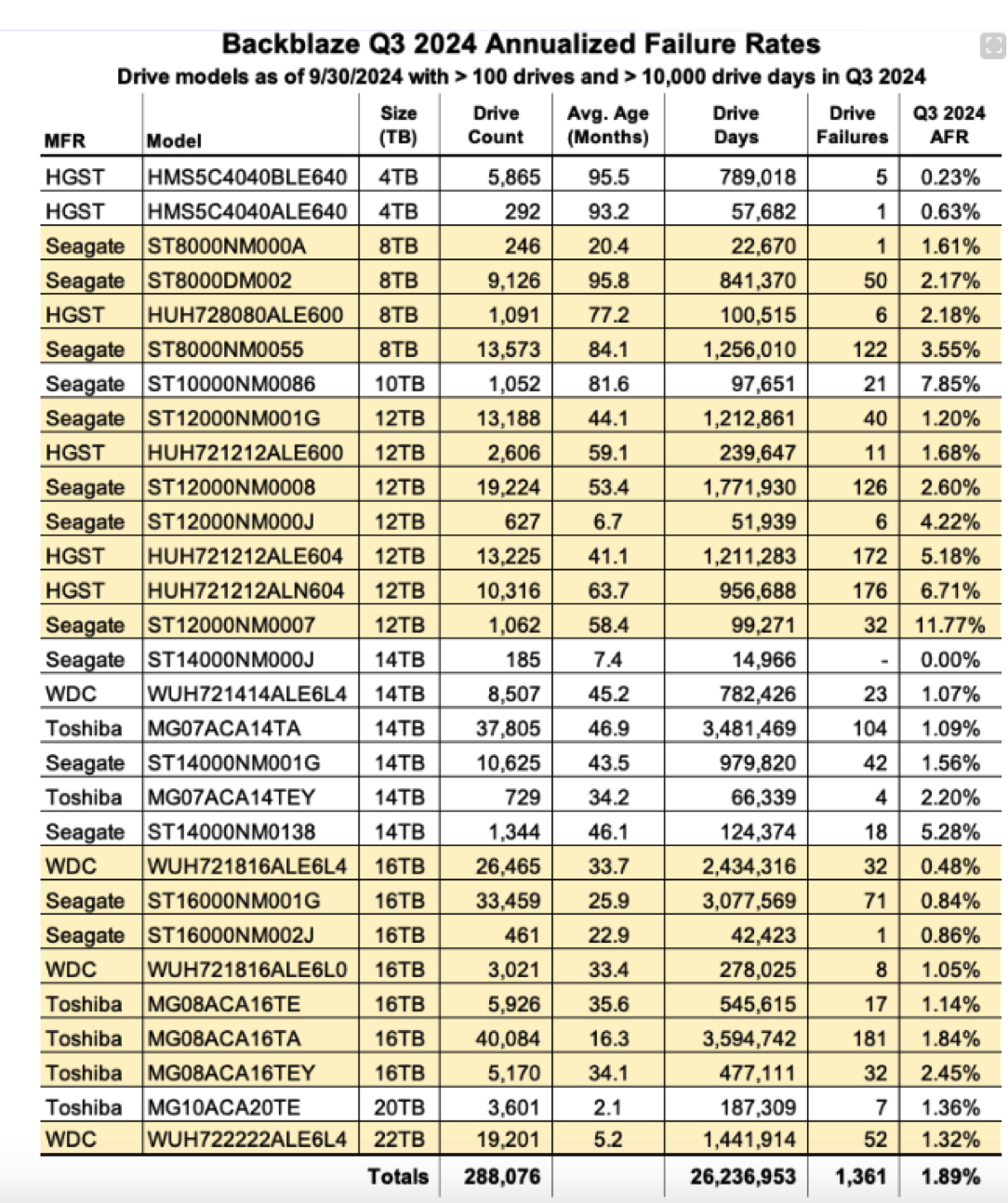
The table below lists the AFRs and related data for these drive models. The table is sorted ascending by drive size then ascending by AFR within drive size.
Notes and observations on the 3Q24 Drive Stats
- Upward AFR. The Q/Q AFR continues to creep up rising from 1.71% in 2Q24 to 1.89% in 3Q24. The rise can’t be attributed to the aging 4TB drives, as our CVT drive migration system continues to replace these drives. As a consequence, the AFR for the remaining 4TB drives was 0.26% in 3Q24. The primary culprit is the collection of 8TB drives, which are now on average over seven years old. As a group, the AFR for the 8TB drives rose to 3.04% in 3Q24, up from 2.31% in 2Q24. The CVT team is gearing up to begin the migration of 8TB drives over the next few months.
- Yet another golden oldie is gone. You may have noticed that the 4TB Seagate drives (model: ST4000DM000) are missing from the table. All of the Backblaze Vaults containing these drives have been migrated, and as a consequence there are only 2 of these drives remaining, not enough to make the quarterly chart. You can read more about their demise in our recent Halloween post.
- A new drive in town. In 3Q24, the 20TB Toshiba drives (model: MG10ACA20TE) arrived in force, populating 3 complete Backblaze Vaults of 1,200 drives each. Over the last few months our drive qualification team put the 20TB drive model through its paces and, having passed the test, they are now on the list of drive models we can deploy.
- One zero. For the 2nd quarter in a row, the 14TB Seagate (model: ST16000NM002J) drive model had zero failures. With only 185 drives in service, there is a lot of potential variability in the future, but for the moment, they are settling in quite well.
- The 9-year club. There are no data drives with 10 or more years of service, but there are 39 drives that are nine years or older. They are all 4TB HGST drives (model: HMS5C4040ALE640) spread across 31 different Storage Pods, in 5 different Backblaze Vaults and 2 different data centers. Will any of those drives make it to 10 years? Probably not, given that 4r of the 5 vaults have started their CVT migrations and will be gone by the end of the year. And, while the 5th vault is not scheduled for migration yet, it is just a matter of time before all of the 4TB drives we are using will be gone.
Reactive and proactive drive failures
In the Drive Stats dataset schema, there is a field named failure, which displays either a 1 for failure or a 0 for not failed. Over the years in various posts, we have stated that for our purposes drive failure is either reactive or proactive. Furthermore, we have suggested that failed drives fall basically evenly into these 2 categories. We’d like to put some data behind that 50/50 number, but first let’s start by defining our 2 categories of drive failure, reactive and proactive.
- Reactive: A reactive failure is when any of the following conditions occur: the drive crashes and refuses to boot or spin up, the drive won’t respond to system commands, or the drive won’t stay operational.
- Proactive: A proactive failure is generally anything not a reactive failure, and typically is when one or more indicators such as SMART stats, FSCK (file system) checks, etc., signal that the drive is having difficulty and drive failure is highly probable. Typically a multitude of indicators are present in drives declared as proactive failures.
A drive that is removed and replaced as either a proactive or reactive failure is considered a drive failure in Drive Stats unless we learn otherwise. For example, a drive is experiencing communications errors and command timeouts and is scheduled for a proactive drive replacement. During the replacement process, the data center tech realizes the drive does not appear to be fully seated. After gently securing the drive, further testing reveals no issues and the drive is no longer considered failed. At that point, the Drive Stats dataset is updated accordingly.
As noted above, the Drive Stats dataset includes the failure status (0 or 1) but not the type of failure (proactive or reactive). That’s a project for the future.
To get a breakdown of different types of drives failure we have to interrogate the data center maintenance ticketing system used by each data center to record any maintenance activities on Storage Pods and related equipment. Historically, the drive failure data was not readily accessible, but a recent software upgrade now allows us access to this data for the first time. So in the spirit of Drive Stats, we’d like to share our drive failure types with you.
Drive failure type stats
3Q24 will be our starting point for any drive failure type stats we publish going forward. For consistency, we will use the same drive models listed in the Drive Stats quarterly report, in this case 3Q024. For this period, there were 1,361 drive failures across 29 drive models.
We actually have been using the data center maintenance data for several years as each quarter we validate the failed drives reported by the Drive Stats system with the maintenance records. Only validated failed drives are used for the Drive Stats reports we publish quarterly and in the data we publish on our Drive Stats webpage.
The recent upgrades to the data center maintenance ticketing system have not only made the drive failure validation process easier, we can now easily join together the two sources. This gives us the ability to look at the drive failure data across several different attributes as shown in the tables below. We’ll start with the number of failed drives in each category and go from there. This will form our baseline data.
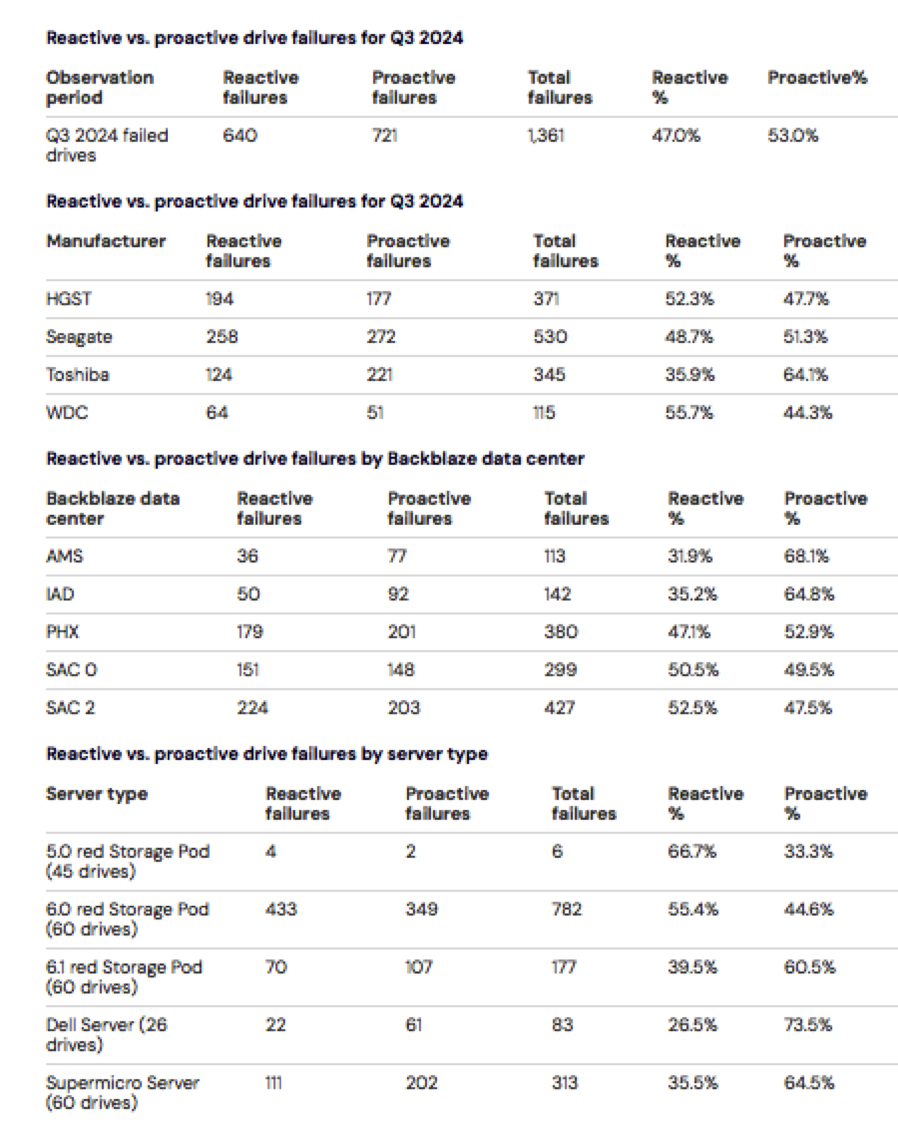
Obviously, there are many things we could analyze here, but for the moment we just want to establish a baseline. Next, we’ll collect additional data to see how consistent and reliable our data is over time. We’ll let you know what we find.
Learning more about proactive failures
One item of interest to us is the different reasons that cause a drive to be designated as a proactive failure. Today we record the reasons for the proactive designation at the time the drive is flagged for replacement, but currently multiple reasons are allowed for a given drive. This makes determining the primary reason difficult to determine. Of course, there may be no such thing as a primary reason, as it is often a combination of factors causing the problem. That analysis could be interesting as well. Regardless of the exact reason, such drives are in bad shape and replacing degraded drives to protect the data they store is our first priority.
Lifetime hard drive failure rates
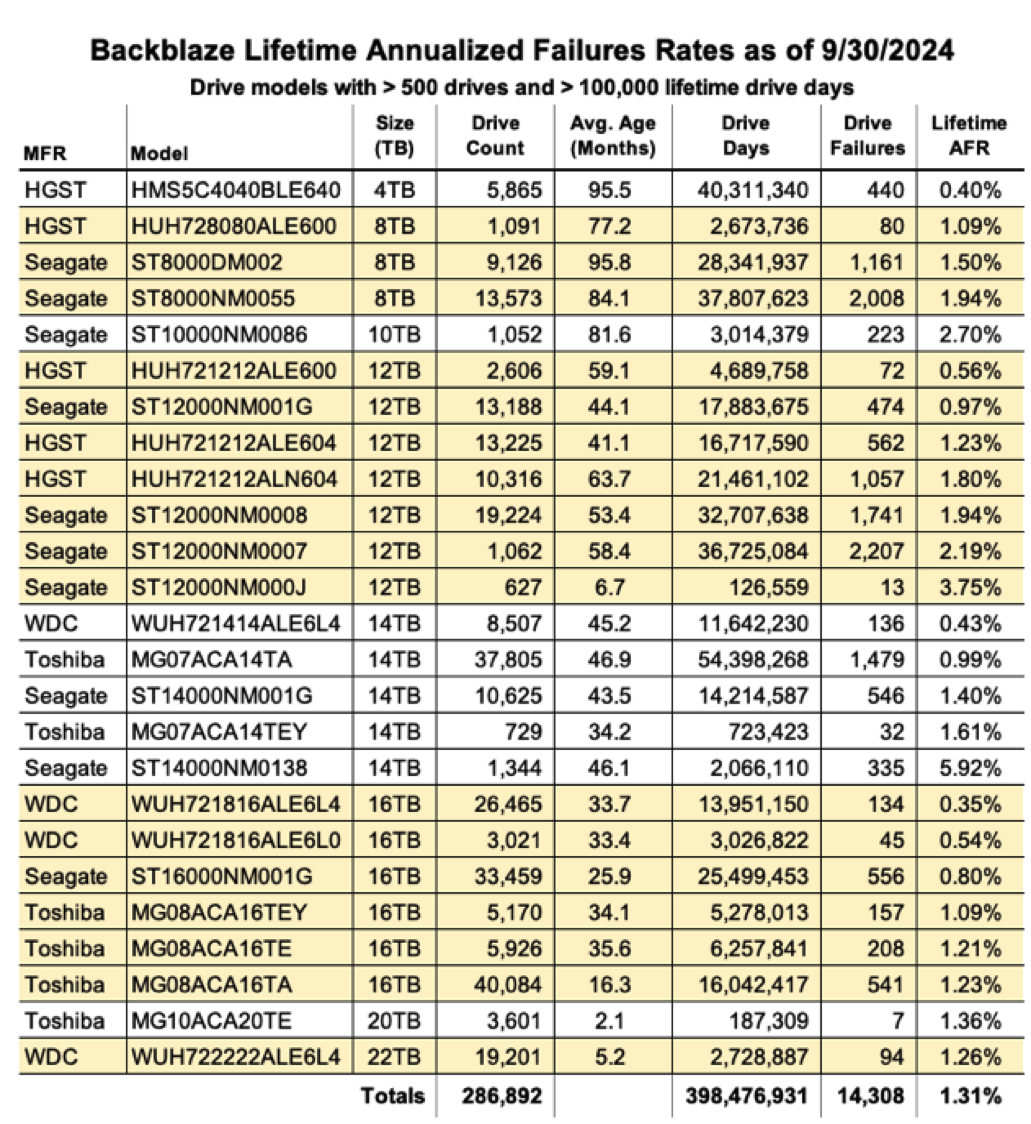
As of the end of 3Q24, we were tracking 288,547 operational hard drives. To be considered for the lifetime review, a drive model was required to have 500 or more drives as of the end of 3Q24 and have over 100,000 accumulated drive days during their lifetime. When we removed those drive models which did not meet the lifetime criteria, we had 286,892 drives grouped into 25 models remaining for analysis as shown in the table below.
Downward lifetime AFR
In 2Q24, the lifetime AFR for the drives listed was 1.47%. In 3Q24, the lifetime AFR went down to 1.31%, a significant decrease from one quarter to the next for the lifetime AFR. This decrease is also contrary to the increasing quarterly AFR increase over the same period. At first blush, that doesn’t make much sense as an increasing quarter-to-quarter AFR should increase the lifetime AFR. There are 2 related factors which explain this seemingly contradictory data. Let’s take a look.
We’ll start with the table below which summarizes the differences between the 2Q24 and 3Q24 lifetime stats.
 To create the dataset for the lifetime AFR tables two criteria are applied: first, at the end of a given quarter, the number of drives of a drive model must be greater than 500, and, second, the number of drive days must be greater than 100,000. The 1st criterion ensures that the drive models are relevant to the data presented; that is, we have a significant number of each of the included drive models. The 2nd standard ensures that the drive models listed in the lifetime AFR table have a sufficient number of data points; that is, they have enough drive days to be significant.
To create the dataset for the lifetime AFR tables two criteria are applied: first, at the end of a given quarter, the number of drives of a drive model must be greater than 500, and, second, the number of drive days must be greater than 100,000. The 1st criterion ensures that the drive models are relevant to the data presented; that is, we have a significant number of each of the included drive models. The 2nd standard ensures that the drive models listed in the lifetime AFR table have a sufficient number of data points; that is, they have enough drive days to be significant.
As we can see in the table above, while the number of drives went up from 2Q24 to 3Q24, the number of drive days and the number of drive failures went down significantly. This is explained by comparing the drive models listed in the 2Q24 lifetime table versus the 3Q24 lifetime table. Let’s summarize.
- Added: In 3Q24, we added the 20TB Toshiba drive model (MG10ACA20TE). In 2Q24, there were only 2 of these drives in service.
- Removed: In 3Q24, we removed the 4TB Seagate drive model (ST4000DM000) as there were only 2 drives remaining as of the end of 3Q24, well below the criteria of 500 drives.
When we removed the 4TB Seagate drives, we also removed 80,400,065 lifetime drive days and 5,789 lifetime drive failures from the 3Q24 lifetime AFR computations. If the 4TB Seagate drive model data (drive days and drive failures) was included in the 3Q24 Lifetime stats, the AFR would have been 1.50%.
Why not include the 4TB Seagate data? In other words, why have a drive count criteria at all? Shouldn’t we compute lifetime AFR using all of the drive models we have ever used which accumulated over 100,000 drive days in a lifetime? If we did things that way, the list of drive models used to compute the lifetime AFR would now include drive models we stopped using years ago and would include nearly 100 different drive models. As a result, a majority of the drive models used to compute the lifetime AFR would be outdated and the lifetime AFR table would contain rows of basically useless data that has no current or future value. In short, having drive count as one of the criteria in computing lifetime AFR keeps the table relevant and approachable.
The Hard Drive Stats data
It has now been over 11 years since we began recording, storing, and reporting the operational statistics of the HDDs and SSDs we use to store data at Backblaze. We look at the telemetry data of the drives, including their SMART stats and other health related attributes. We do not read or otherwise examine the actual customer data stored.
Over the years, we have analyzed the data we have gathered and published our findings and insights from our analyses. For transparency, we also publish the data itself, known as the Drive Stats dataset. This dataset is open source.






 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

