







Object Storage, We Should Say S3 Storage, Reaches New Level
Sign of maturity?
By Philippe Nicolas | June 7, 2024 at 2:01 pmObject storage had ups and downs since its early days, we all have in mind projects, initiatives or companies at the end of the 90’s and beginning of 2000’s with HTTP-based access that targeted archiving with a disk-based model. Then, a wave of vendors, some new, and the official Amazon S3 launch in 2006 that triggered a real new era of storage with what we called more recently Software-Defined Storage (SDS), at least for the object side. Long story short, we invite you to check the timeline below, produced by Coldago Research. Readers probably also remember the article we wrote in 2019 named “Object Storage Dead, S3 Eats Everything“.
Click to enlarge

In parallel, more than 10 years ago, we remember some vendors claiming to replace NAS and SAN with object storage. That shift didn’t happen even if we saw S3 storage adoption of course, NAS are stronger than ever. But even if HTTP became a “storage protocol” since AWS launched S3, how can an object storage solution replace a block storage as the access methods are really different. Object storage is of course not a NAS, the access method is very different, there is no locking as the last write wins. What people had in mind was the potential consideration of object storage for some primary and secondary storage use cases.
Originally when object storage was introduced, it was a way to address NAS and file servers limitations in terms of capacity and scalability with file and file system sizes and file numbers, based on a radical new design with some key characteristics such as flat name space. But one of the most significant elements is what we call vertical versus horizontal consistency independently of the CAP theorem. Normally, when you have a volume and a file system above a volume, it is required that each layer maintains its own consistency with the minimum number of volume components and file system structure to make viable the service. At scale, and even more with scale-out or multi-node configurations and we don’t speak about multi-site that can create real divergence, it can represent a real challenge and classic models simply don’t fit. For object storage, what is important is to reach and serve the content from its object ID and this vertical connection from the front-end to the physical locations of that content with all needed management and control. This navigation doesn’t require all components available at each layer. This is the result of a different philosophy with every disk unit managed independently, for some products each disk is used with a file system on it or as raw device for other implementations. The consequence is that data protection has been extended and we, very often, associated erasure coding market expansion with object storage. It is true even if erasure coding is not linked to object storage, we all remember that Isilon in 2001 was delivered with a Reed Solomon based model before the main object storage wave and also some object storage that offered only replication for several years appeared later. Today, and for a few years, erasure coding is everywhere.
Object storage became very popular and, as said, we speak today more about S3 storage as S3 reached a de facto standard status.
One key evolution is represented by the capability to access the same content from an industry standard file sharing protocol like NFS or SMB and the S3 API.
Use cases can be very diverse, from primary to secondary storage needs as the model became universal. The partner ecosystem is key as S3 integration represents a significant go-to-market and vehicle for the adoption. What has surprised us is the shift some vendors have made with a focus on data protection as a backup or even an archive target. Obviously, S3 storage is a good candidate especially when durability is maximized with erasure coding and a few other adjacent mechanisms.
The next step also was a surprise for many of us when we read that object storage needs to be protected by a tape library breaking the data durability message of object storage but we understand the opportunity it could represent for tape vendors. The convergence of this culminates with the S3-to-Tape, a sort of VTL 2.0, that presents a tape library as a S3 storage with one key characteristic; it is based on HTTP so it is remotely addressable.
On the other extreme, beyond this capacity oriented and tape connected models, some vendors have designed object storage offerings with flash, NVMe, containerization, fast networks, new key-value (transactional) storage layer… to serve high demanding workloads still with a S3 interface.
The last surprising development is the simple node design disconnected from the original model of object storage. The durability promise with erasure coding across a multi node architecture disappears. Obviously edge offers opportunities and users ask for S3 whatever is the back-end, it can be offered on top of many different flavors of storage.
And we must speak about open source that has a place in this segment with some famous products.
As said, we speak today about S3 storage confirming that object storage is now an interface and no longer an architecture or an internal design. As a reminder, an object doesn’t exist outside the system that defines and stores it.
All these movements and developments illustrate perfectly what we defined for years with the U3 – Universal, Unified and Ubiquitous – model.
Click to enlarge
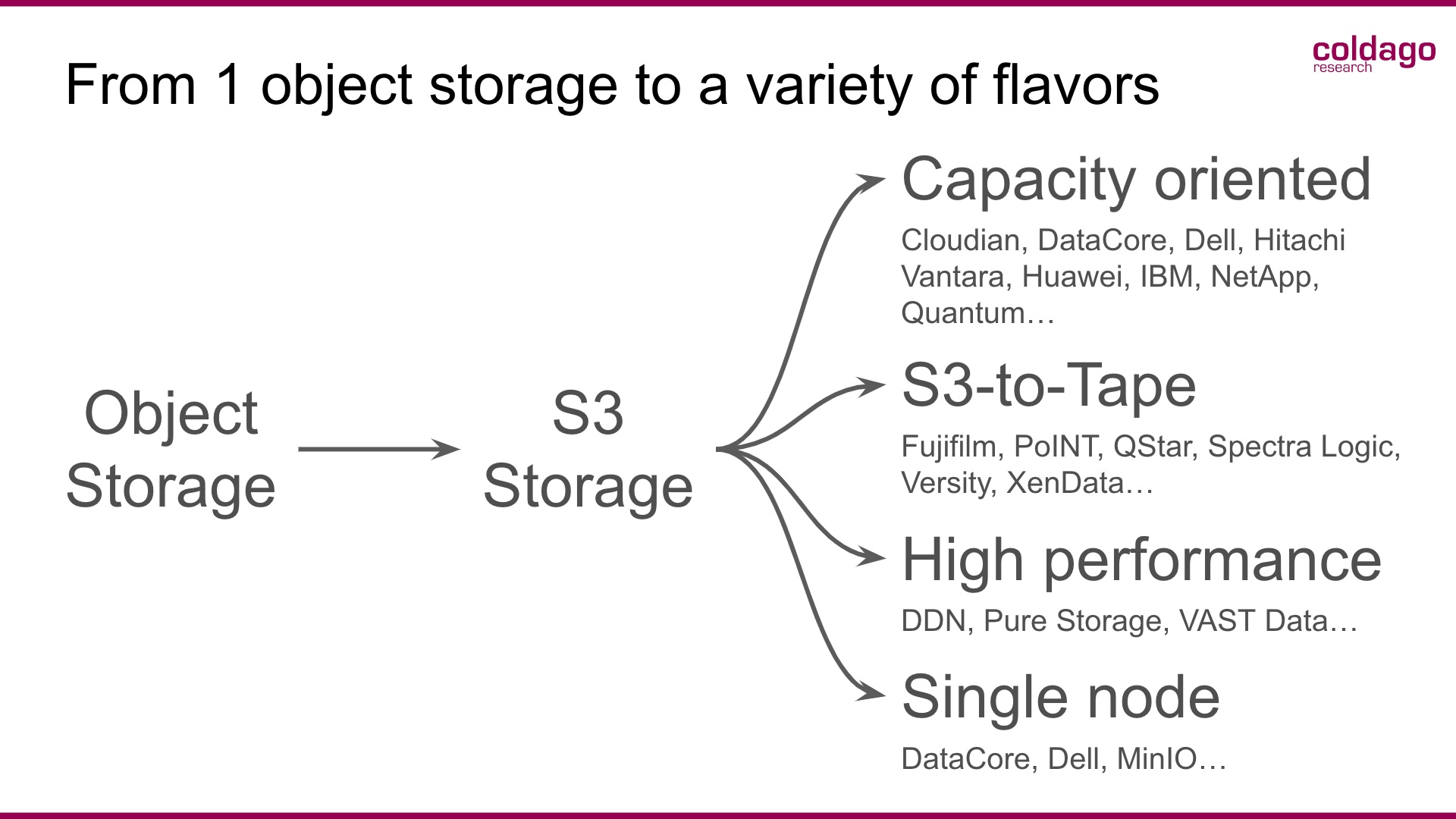
Object Storage again S3 Storage has 4 flavors today:
- Capacity oriented with players like Cloudian, DataCore, Dell, Hitachi Vantara, Huawei, IBM, NetApp or Quantum, etc.
- S3-to-Tape with more than 10 players such as Fujifilm, PoINT Software and Systems, QStar, Spectra Logic, Versity or XenData, etc.
- High performance with DDN, Pure Storage, or Vast Data, etc., and
- Single node with DataCore, Dell or MinIO, etc.






 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter


