





To Clarify Few Things on File Systems
As some confusion exists for parallel file system
By Philippe Nicolas | June 26, 2023 at 2:02 pmFollowing some recent vendors’ messaging, marketing pitches and press articles promoting parallel and network file systems in a strange way, we wrote this piece to clarify a bit the file systems domain. In other words, it’s important to understand from where people speak, what is their interest and value to say that based on what they offer and their associated limitations or properties.
We realize that many people don’t know what a parallel file system is and why the industry invented this model. Historically and to make that part brief, some users, especially where data was big in size both in terms of capacity but also in terms of file size, touched a problem. How is it possible to boost the file read and write operations? Research centers and technical environments encountered this reality earlier than others and they tried to address this limitation. Based on the same “divide and conquer” model, the idea was to store portions of the file on different storage entities but not like RAID between disks but between file servers and we can potentially say “RAIN zero” to maintain some analogy. Of course on the back-end, a file can be split into multiple subparts but it is not the purpose of my point here. With a special software piece installed on client machines, users and applications can now read and write files in parallel as the striping is made and controlled by the client, it knows the file layout and the file servers environment with some manifest files or side metadata servers. It was the genesis, then some people industrialized this and we know for many years models like Lustre, the open source reference in parallel file system, followed by several commercial implementations or similar philosophies.
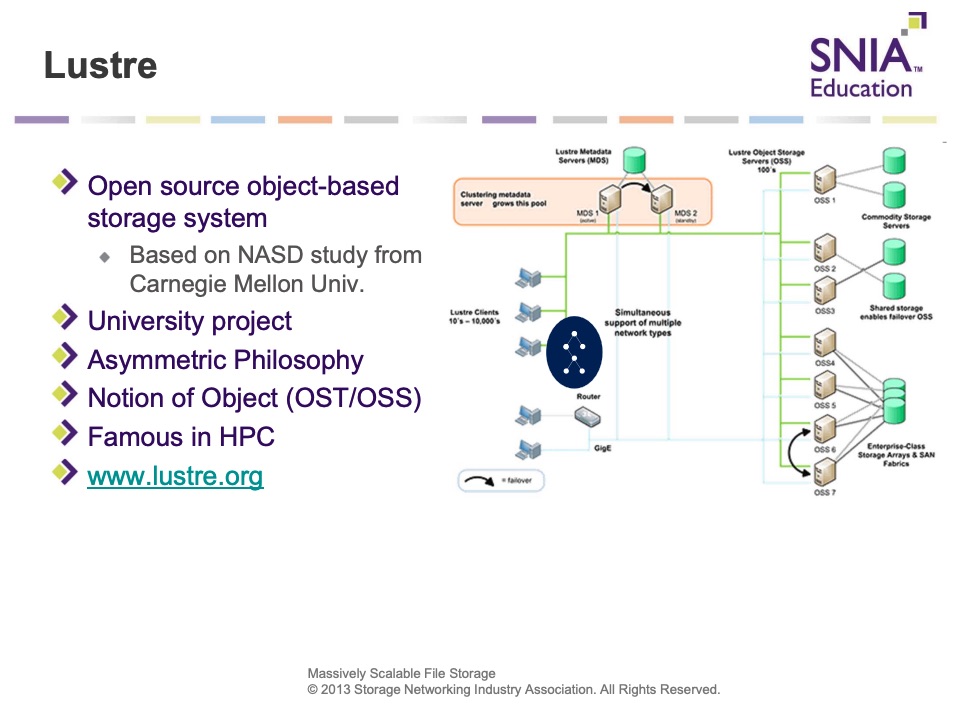
This model arrived after Sun Microsystems introduced NFS in the mid 80s, almost 40 years ago, but it was a single file server model where all the file is transferred via a unique machine. In other words at that time the model named client-server allowed one file server connected to multiple clients, and believe me, it changed how people worked for decades. The good thing is, NFS was and still is an industry standard, nothing to install on clients or even servers. The good source of info still is the RFC 1813.
Around early 2000, some people tried to mix both approaches saying in a nutshell that a parallel NFS should be a good idea, being a standard and delivering real performance boost. It never took off and some companies like Isilon or Spinnaker Networks tried to invent a new model still based on the NFS standard.
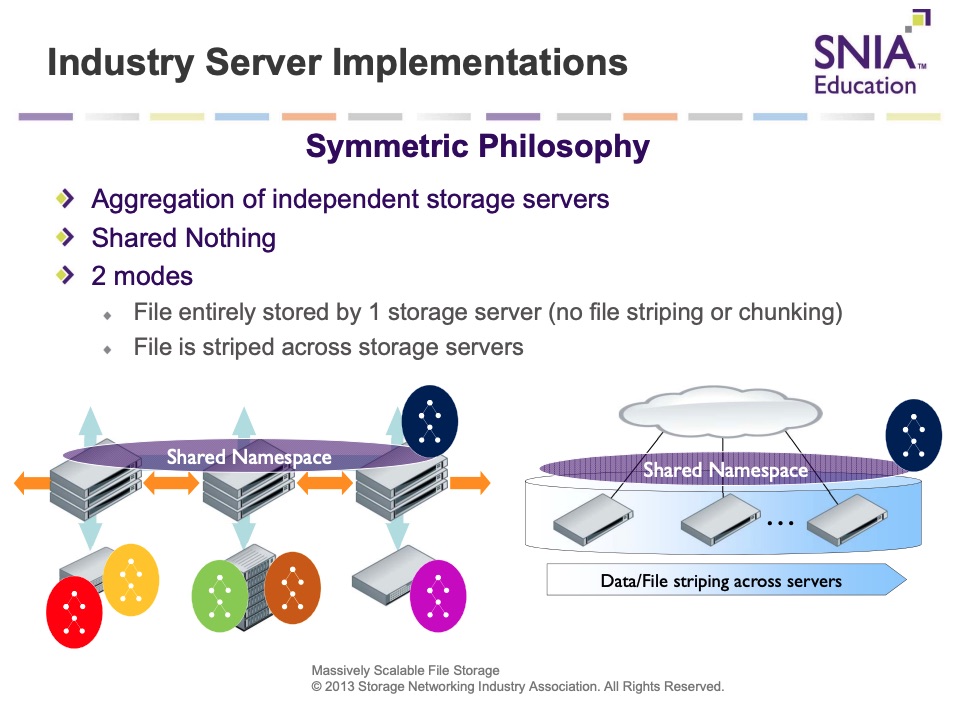
For Isilon, the idea was to build a scalable access layer with multiple servers each with internal disk, each of these servers expose the same view of the file system externally. This access of a file is done by only one server, we mean when a client writes a file, only one server is involved, all data transits through it, and then this server stripes and sends data chunks to other servers via its private network between nodes. This is what we called a “stripe behind” approach. Now to read a file, a client can pick any server and again the entire file is served from this entry cluster point, this server is responsible to collect data from other servers from this private network. This is a simple NFS with resiliency based on Erasure Coding in the early 2000, capacity scaling with node addition and throughput with multiple access points. But even if it was not parallel it was a great progress.
Spinnaker Networks was different as a file belongs to only one server but can be served by multiple front-end servers with the active use of a private network between these systems. Both models are considered as scale-out in a shared-nothing philosophy. We know the end of these stories, Spinnaker Networks was swallowed by NetApp in 2004 for $300 million and Isilon was acquired by EMC in November 2010 for $2.25 billion. These technologies and products have been key for file servers developments at respective companies for sure.
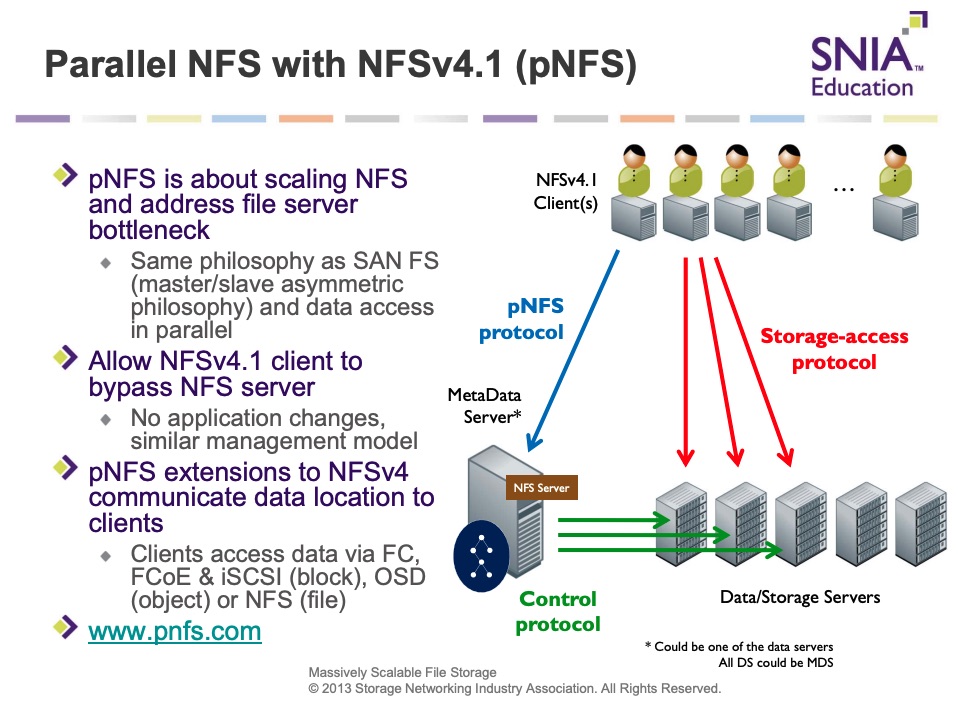
Parallel file systems continue to be developed and improved. We saw various implementations, still some open source, private or commercial ones. Same remark for pNFS, standard in the Linux kernel and supported by various file servers vendors. It’s an official standard with various layout capabilities and different data server flavors.
The aspect in pNFS or other parallel file systems is the role of the client machine to split, stripe or chunk data and then send it over to multiple data servers. This client machine can use a standard component like pNFS or install a special driver or agent responsible for that. Of course, the parallel file system model relies on metadata and data servers, deployed on same or distinct systems. Both entities are scalable and of course introduce their own limitations and properties.
One of the key points was how these implementations manage cache, write latency, change propagation, locking and how they present a single file system image from any node at any given point in time? This was a serious concern especially as configuration continues to grow due the explosion of data volumes and data divergence can’t be accepted. In other words, when configurations are small, they’re manageable but sooner or later due to traffic and volumes, it’s tough and touches the impossible.
The battle against NFS was over and research centers or organizations with high demanding I/O requirements picked a parallel file system. Historically, people thought that the problem came from NFS itself.
But a few events and new technologies have changed this paradigm, flash, persistent memory, NVMe and its network companion emerged and even if they can be used also for parallel file system, they invited some engineers to think about a NFS-based file service, a new one, a radical new animal, that should bring back NFS in the forefront of the market.
Of course, NFS is NFS if we can say that; a file is still served by only one server if pNFS is not used. But let me detail some enhancements the industry has added to NFS to improve its performance capabilities especially in a scale-out world.
Historically we found UDP implementation, non connected mode, but for some years TCP, connection mode, was clearly the preferred choice. On the TCP implementation side, NFS uses by default 1 session on a single port. NFS on TCP used for quite some time sessions and users can define on the client side with the nConnect mount option up to 16 of them, the best result seems to be 8. It supports NFS v3 and v4, runs Linux kernel 5.3 and it was back ported as well.
This multiple connection feature augments the throughput even with one file server and clearly gains are significant to a few GB/s to a virtual IP but IO/s doesn’t change as only one server is used. It still is 1 mount, 1 client, 1 server with multiple sessions.
An interesting thing to notice is that nConnect is not compatible with Kerberos and it could introduce some problems in some critical environments.
Now we can multiply connections to a single server with nConnect, we need potentially multiple connections to multiple links to the same server. This is what NFS introduced with Multipathing available for v3 and v4.1. As a summary it is 1 port, n links, up to 8, on the client or on still a single server.
And the result is very impressive when you combine nConnect and Multipathing passing 100GB/s easily of course based on the network capabilities. In that case, you multiply the port with nConnect and you combine this with the multiple links, having a double effect, but still with one NFS server.
And if you need to now add multiple servers, you need some additional service layer to expose a single file system view to client from various NFS heads. But we can imagine the performance you could receive from this. Now it’s important to understand that a file is still going to one head even if multiple heads can receive different files in parallel. So the parallelism is obtained across files not within a file and for large file and some vertical domains, this is needed to reduce latency and gain throughput.
Another key flavor is the coupling of NFS and RDMA to replace TCP thus reducing significantly latency and improving global throughput for some high demanding I/O needs. For sure, it requires some specific hardware with specific NIC, network, driver and configurations to enable this environment. NFSoRDMA is specific and requires special modules on clients.
And some vendors have successfully combined RDMA and Multipath with, of course, a specific client software set.
And the last possible NFS configuration is related to GPU with Nvidia GPUDirect Storage aka GDS working with RDMA of course. These configurations like the Nvidia SuperPOD work with parallel file systems and NFS. A few file storage vendors have validated these configurations certified by Nvidia.
We’re always surprised to see people who worked for parallel file system vendors trying to destroy NFS at that time being now at NFS vendors doing the reverse battle. Funny situation and not very serious but giving the image of a big lack of consistency and opportunism. In other words, these people are simply burned and lost all their credibility even if we all can change our opinion.
Some vendors have introduced their own NFS stack that requires an installation on clients’ side and therefore produce the same intrusive effect like a parallel file system driver. We understand why this argument was not promoted. But it provides a set of features not available with the installed default file service layer.
The parallel file system model relies on clients that stripe files across back-end data servers without any specific network. File chunks, fragments or segments are distributed across all these servers controlled by the client. With NFS nConnect + Multipathing, the file is untouched by the client and the file physical allocation relies on the server plane below NFS that can potentially stripes across disks and/or participants. In other words, the storage software layer is responsible for that and it is fully independent of the client and the access protocols.
Parallel file system is about file organization, adding some parallelism to NFS on the access mode doesn’t mean NFS becomes parallel. Again if NFS is considered parallel it is when people refer to pNFS. To be clear again, if users needs parallelism globally across files, nConnect + Multipathing is appropriate, if users require distribution of files’ part across back end servers, pNFS is the right choice.
Another way to explain this invites us to introduce what we call internal and external file systems, a notion considered from a client machine point of view. It’s about replying to the question how is that client connected to the file system.
An internal file system is limited to a server – in that case, it is often assimilated to a disk file system or to the file organization on devices or a set of servers and between them in the case of scale-out NAS and exposed outside via a software client, called an agent or driver, like a Posix client for parallel file systems we already mentioned above. This client understands the file system layout via its link to metadata servers, it belongs to it in a sense.
On the other hand, an external file system is a file system that introduces a disconnect between a disk file system or an “internal” file system and an presentation layer like NFS or SMB. A client machine doesn’t understand the file system but interacts with it via this access layer. These NAS protocols are responsible to expose file system externally via an export operation and they finally virtualize it.
The file storage market once again demonstrated its value, keeping things simple and standard on the access layer and leveraging latest technologies on flash, persistent memory, NVMe and its networking companion.
And we found a vendor who promotes a parallel global file system, a positioning that adds some confusion to the game, not sure the industry needs this kind of messaging iteration.
To conclude, let us name products in each category to align what we said with the market reality and obviously we don’t mention disk file system or cloud file storage solutions to avoid any additional confusion:
- ThinkParQ with BeeGFS, The open source Lustre, DDN with ExaScaler based on Lustre, IBM with Storage Scale, Weka, Panasas, Quobyte, HPE with Cray ClusterStor or projects like PVFS are all parallel file system. Hammerspace is promoting pNFS, an industry standard extension of NFS. Fujitsu, NEC or Huawei also add some parallel file system flavors. Some of them add a NFS and SMB profile but philosophically, they’re fundamentally parallel animals.
- All products exposing NFS and SMB with unified storage included belong to the file servers and NAS category. It is the case for Dell with PowerScale for instance, NetApp of course, Pure Storage with FlashBlade and FlashArray, Quantum with Myriad, Qumulo, Vast Data, Tintri, Nexenta, iXsystems with TrueNAS, Veritas with InfoScale or Microsoft with Scale-Out File Server. Of course take just a Linux distribution and expose a local file system via NFS give to the system a file server behavior.



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

