







Cloudera Kudu, Hadoop Storage for Fast Analytics on Fast Data
Open source project in public beta to enable real-time analytic applications in Hadoop
This is a Press Release edited by StorageNewsletter.com on October 9, 2015 at 2:38 pmCloudera, Inc. announced the public beta release of Kudu, a columnar store for Hadoop that enables the combination of fast analytics on fast data.
![]()
Complementing the existing Hadoop storage options, HDFS and Apache HBase, Kudu is the first native Hadoop storage engine that supports both low-latency random access and high-throughput analytics, simplifying Hadoop architectures for increasingly common real-time use cases. A public beta of Kudu is available under the Apache open source license, and will be transitioned to the Apache Software Foundation incubator in the future.
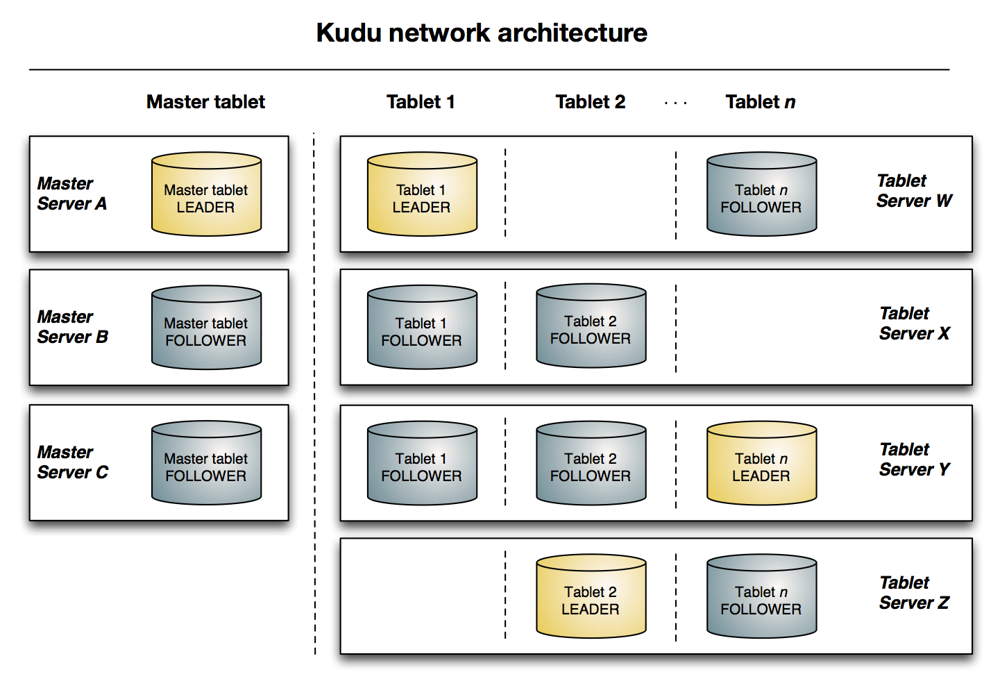
Developers have been forced to make a choice between fast analytics with HDFS or efficient updates with HBase. Especially with the rise of streaming data, there has been a growing demand for combining the two features to build real-time analytic applications on changing data – leading developers to create complex architectures with the storage options available. Kudu complements the capabilities of HDFS and HBase, providing simultaneous fast inserts and updates and efficient columnar scans. This powerful combination enables real-time analytic workloads with a single storage layer, eliminating the need for complex architectures.
“We’ve been making Hadoop better since the very beginning,” said Charles Zedlewski, VP, products, Cloudera. “We have an ambitious mission: to constantly drive innovation within the community to usher in the next-generation of analytics supported by Hadoop, so companies can adapt to the latest technologies. Cloudera has already transformed what’s possible with Hadoop – enabling interactive data discovery and analytics with Impala and flexible data processing and streaming with Apache Spark. Kudu continues this trend by revolutionizing Hadoop’s storage architecture to better support development of real-time analytic applications, and serves as a crucial step towards solidifying Hadoop as leading platform for modern analytics.“
Kudu’s architecture streamlines the developer experience for building analytic applications – supporting common use cases that include time series analysis, machine data analytics, and online reporting. Additionally, Kudu is designed to take advantage of changing trends in hardware and in-memory processing. It delivers outstanding CPU performance, takes advantage of RAM and Flash, and drives high I/O efficiency as a true columnar store. Finally, as a native, open component within Hadoop, Kudu is integrated with and provides faster query performance for the most powerful analytic frameworks. Users already rely upon many of them, including Impala and Spark – for end-to-end analytic applications in a single platform.
Kudu was jointly engineered by Cloudera and Intel Corp. in advance of the changing hardware landscape. Intel has actively contributed to Kudu to help it take advantage of current and future Intel processor and memory technologies. Kudu was designed to use persistent memory (pmem) innovations being developed through Intel’s pmem project.
Kudu Tracing
Click to enlarge
“As Hadoop analytics evolve, it’s critical that they are designed with next-generation hardware in mind,” said Vin Sharma, director, strategy and products for big data analytics, Intel. “Kudu is a critical milestone for Hadoop, supporting the growing need for simplified real-time applications. Intel worked with Cloudera and the community to ensure Kudu is optimized for fast analytic performance today, but is also built to use Intel’s platform advancements well into the future, such as Intel DIMMs with 3D XPoint memory.“
As an open source project, Kudu has drawn wide involvement from the community. Xiaomi, Inc., one of the largest smartphone developers in the world, has been one of the first beta users of Kudu and actively contributing to the project. Other organizations, including AtScale, Splice Machine, Inc. and Zoomdata, have also been developing on Kudu.
“Xiaomi has been a long-time user of and contributor to the Hadoop ecosystem, using it to power a wide range of use cases across our business,” said Baoqiu Cui, chief architect, Xiaomi. “Our infrastructure team has been working with Cloudera to develop Kudu, taking advantage of its unique ability to support columnar scans and fast inserts and updates to continue to expand our Hadoop ecosystem footprint. Using Kudu, alongside interactive SQL tools like Impala, has allowed us to build a next generation data analytics platform for real-time analytics and online reporting. We are excited to continue to work with the community to further drive Kudu and the capabilities of Hadoop as a whole.”
“Kudu effectively enables the next-generation of analytic architectures, especially for Business Intelligence (BI). With its support for both random and sequential high volume reads and writes, it is the ideal storage system for low-latency, scale-out BI architectures of the kind that AtScale customers demand. As enterprises look to democratize access to data and enable Hadoop to run large-scale, fast analytical workloads, Kudu will play a critical role,” says Josh Klahr, VP, product management, AtScale. “As a strong proponent of the Apache Hadoop open source ecosystem, AtScale is to be a part of this community effort and excited to help further develop it for our customers.“
“We are very excited to be part of the Kudu community,” said John Leach, co-founder and CTO, Splice Machine “At Splice Machine, we have developed an ACID compliant RDBMS that runs on Hadoop and are pushing the envelope in terms of running mixed workloads on Hadoop. As a result, we welcome and support innovation in Hadoop’s storage architecture. Kudu holds incredible promise in its ability to handle real-time updates combined with long-running analytics. It strengthens the Hadoop ecosystem by providing a scalable, alternate storage engine that complements existing ones.“
“Kudu provides a simplified storage architecture for use cases that are quite common among Zoomdata users,” said Justin Langseth, CEO, Zoomdata, Inc. “As a native component of Hadoop, Kudu’s integration with Impala and Spark make it easy to open up this data using Zoomdata’s fast visual analytics solution. We have worked closely with Cloudera and the community to help develop Kudu to meet the needs of our users – supporting the streamlined combination of real-time and analytic applications – and we are excited to continue this effort with the public beta release.”
For organizations to continue to benefit from data-driven insights, Hadoop’s architecture has to work at the same, ever-accelerating speed at which data is being created and changing. With Kudu, the Hadoop community ushers in the next generation of Hadoop applications with storage for fast analytics on fast data.
“In the era of machine-generated data, there’s an increasing need to analyze data in human real-time. This is true across a broad range of analytic use cases, from monitoring and business intelligence to predictive modeling and recommendation,” said Curt Monash, president, Monash Research. “Kudu, Spark and the rest of the Hadoop stack are a promising approach toward eventually meeting those needs.“
Resources:
Start contributing
Download public beta or try the VM
Kudu’s technical whitepaper






 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

