







Evolution of All-Flash Array Architectures
Flash to become lower cost media than HDD for almost all storage in 2016
This is a Press Release edited by StorageNewsletter.com on August 21, 2015 at 2:46 pm This article was written by David Floyer, CTO and co-founder of Wikibon.
This article was written by David Floyer, CTO and co-founder of Wikibon.
Evolution of All-Flash Array Architectures
Executive Summary
In 2009, Wikibon projected that flash would be the lower cost alternative for active data. Figure 1 shows Wikibon’s technology projection for pure capacity data. It shows that flash (the blue line) will become a lower cost media than disk (the red line) for almost all storage in 2016, as scale-out storage technologies enable higher levels of data sharing, and lower storage costs.
Figure 1 – Projection of Technology Costs
of Capacity HDDs and Flash Technologies 2015-2020
enlarge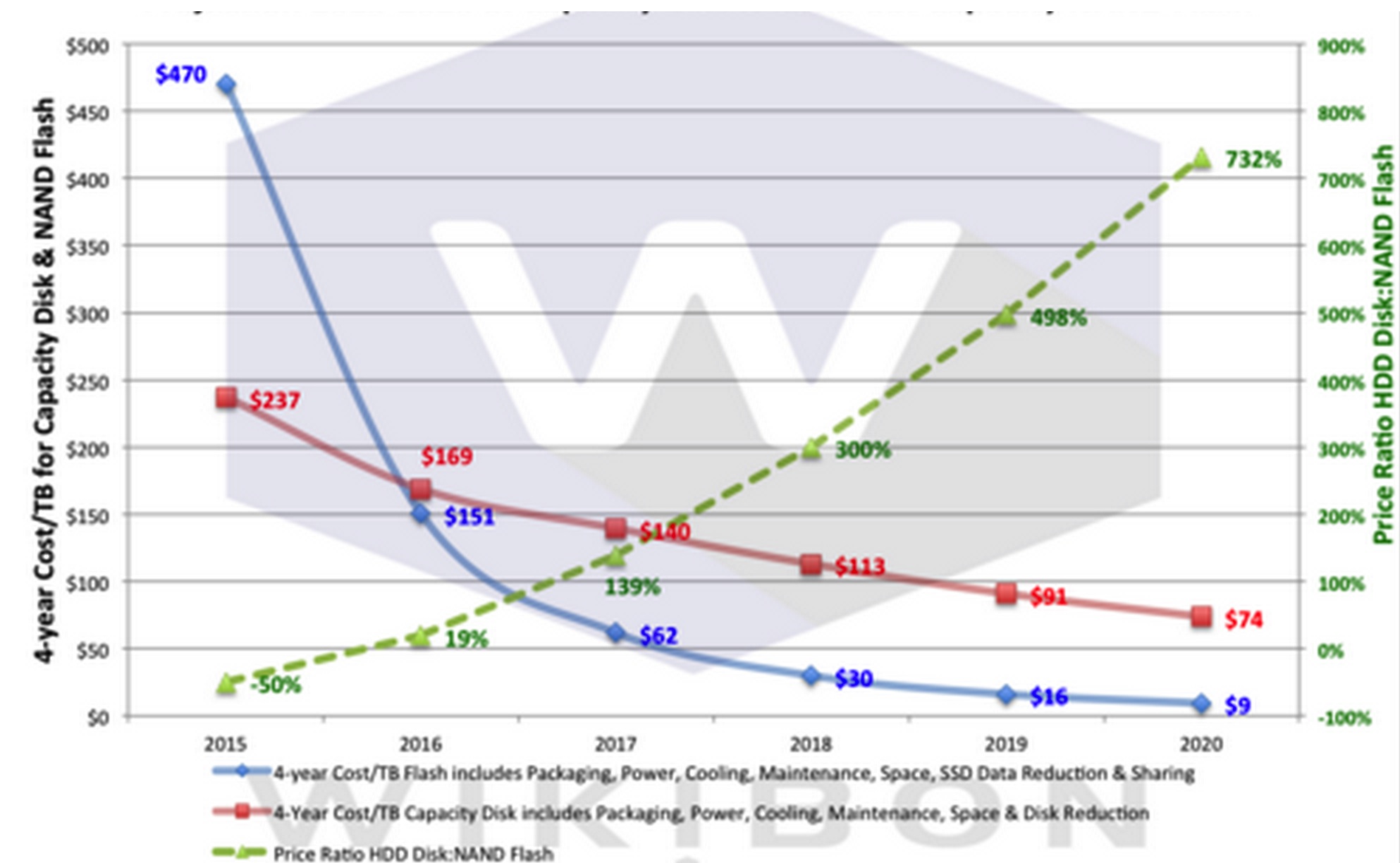
(Source: Wikibon 2015)
The green line shows the ratio between capacity flash and capacity HDD. The is -50% in 2015 (flash is twice the cost). By 2016, flash will be 19% lower cost, and this will grow quickly from 2017-2020.
The keys to achieving the lower costs of flash are:
- Consumer demand for flash that will continue to drive down enterprise flash costs;New scale-out flash array architectures that allow physical data to be shared across many applications without performance impacts;
- New data center deployment philosophies that allow data to be shared across the enterprise rather than stove-piped in storage pools dedicated to particular types of applications.
- This research discusses the key trends in flash and disk technologies in detail and the potential impact of new application design philosophies.
Wikibon concludes that actions are require
by all constituents of the ecosystem to make this happen:
- CXOs and senior enterprise business leaders will need to restore their faith that IT can and will improve its dismal record of delivering on complex deployments. Business game-changing potential waits for enterprises that develop and deploy new data-rich applications that can profoundly improve productivity and revenue potential. These application that combine operation with in-line analytics can only be realized on flash-only shared-data environments.
- IT senior management will need to change and reorganize IT infrastructure management, slim down infrastructure staffing, automate and orchestrate deployment of IT resources, and move rapidly towards a shared data philosophy enabled by flash storage deployment for almost all enterprise data.
- All-flash array vendors and other flash architectures will need to focus on developing scale-out architectures and maximize the potential for data sharing.
The end-point of the adoption of flash-only persistent storage is a completely ‘electronic data center’, with no mechanical components except for a few pumps and fans. Within the electronic data center, electronic storage will allow logical sharing of the same physical data to be fully enabled. CEOs should be asking IT about definitive plans to move to an electronic data ,ter, the timescale of the migration, and information about the first application(s) to employ the electronic storage to improve enterprise productivity and revenue.
The Constraints of Disk Technology on Application Design
When magnetic drum technology was first introduced, access time to data was as fast as the compute technology of its day. The major components were magnetic heads and revolving magnetic media. Compute and persistent storage were balanced, with ten microseconds for compute and ten microseconds for acess to persistent storage.
Over time, disk technology was driven by two factors – the development of better magnetic heads and the development of improved movement of the heads and/or magnetic media. Improved magnetic heads reduced the size of magnetic ‘blob’, so tracks could be closer, with more data per track. The technology to fabricate magnetic heads was the same fundamental technology used to fabricate memory and logic chips. The rate of improvement of magnetic heads followed Moore’s law and until recently improved by 30-35%/year. Data density and the cost/unit of storage has improved in line with compute power. However, the rate magnetic data could be read or written (bandwidth) has only improved by less than the square root of the improvement of the data density (~10-12% per year). The physics of spinning the media faster soon reached a plateau, as the outer edge of disk drives approached the speed of sound. Disks became smaller, heads moved across the magnetic media from one track to another, but nothing has had much impact on the time to access data. Magnetic disks are limited by rotation speed, and access times are measured in milliseconds, while compute cycles are measured in nanoseconds.
The history of storage array development has been the application of technologies to mitigate this disparity in cycle time. Read buffers and smart algorithms attempt to maximize the probability that data required by applications would be found in DRAM. Battery and capacitance protect DRAM write buffers, allowing high burst rates of data to be written with low latency. Sequential data is striped across multiple disk drives to increase data rates. All these technologies help if applications are designed in a certain way, with small working sets and limited functionality. A whole major industrial market and supply chain has been built around ‘standard’ disks from Seagate, HGST, and others housed in disk shelves and surrounded by proprietary software on Intel processors. The proprietary software from EMC, NetApp, HP, IBM, and others has been the ‘glue’ that has allowed high functionality with very high uplifts (10-15:1) on the ‘Fry’s Price’, the base cost of a single disk drive.
The attempts to mitigate the mechanical problems have been significant, but the impact of disk storage limitations on application design has also been stark. As Wikibon has pointed out in previous research, applications have been written and designed with small working sets that fit into small buffers. Write rates have been suppressed to meet the write buffer constraints. The number of database calls within a business transaction have been severely limited by the high variance of disk-based storage; this is necessary in order to reduce operational and application maintenance complexity and cost. Large applications are still designed as a series of modules with loosely coupled databases. Data warehouses and analytics are separated from operational transaction systems.
The bottom line is that current applications are dependent on very complex infrastructure software to mitigate the ever increasing gap between compute and persistent storage cycle times. This complex software is spread between the controllers of storage arrays and ever more complex databases from Oracle, IBM, Microsoft, and others that protect applications. NoSQL databases offer apparent relief for some applications but in most instances just move the complexity from the database back to the programmer. Previous Wikibon research has shown the design of application suites such as SAP and many others are also constrained by disk-based storage, and apparently ‘simple’ projects combining multiple landscapes and integrating business processes are in reality difficult, time-consuming and risky. The cost of developing, operating and managing enterprise applications has became very high. Most of the problems in operating current applications are storage related, and almost all the constraints in application design are storage related. Most DBAs and infrastructure specialists assume disk-based storage is guilty until it proves itself innocent.
The business impact of this is immense. The complexity and resultant cost of deploying additional database, storage array software and storage management software to enable moderate or large-scale applications is very high. The disappointment felt by business leaders in the failure of IT to meet its potential to decrease business costs can be placed squarely in this complexity, caused almost exclusively by the failure of mechanical persistent storage to keep up with compute and network technologies. The magnetic disk drive is the last mechanical device in the path of the electronic data center.
Technology Differences Between Flash and Disk
The following is a summary of the technology differences between flash and disk.
Disk:
- Deals with sequential IO much better than random IO;
- Uses read and write caching (part of the storage controller) to minimize disk access;
- Suffers catastrophic disk failures (whole disk fails and needs replacement);
- Is costly in maintenance, power and space;
- Requires near infinite reads and writes to the magnetic media;
- Has grown capacity and cost/GB according to Moore’s law until recently;
- Has grown bandwidth and access density according to the square root of Moore’s law;
- Has failed to improve access latency appreciably;
- Has all but disappeared from high-end PCs, which are usually flash-only;
- Seagate hybrid drives are found in a few low-end consumer PCs, but has not been adopted enterprise datacenter environments;
- Is employed in data centers for active data but needs significant storage administrators, system administrators and DBA’s to manage performance
Flash:
- Deals with reads faster than writes;
- Deals with random IO very well;
- Fails gradually with predictable flash cell decay rates – failure of a total drive extremely unlikely;
- Supports very high number of reads and limited number of writes to the media;
- Improves capacity, access times, access density and bandwidth in line with Moore’s law;
- Can be architected with very low latency and low latency variance (jitter);
- Has very low maintenance (not yet passed on by vendors), and very low power & space costs.
The bottom line is flash is not ‘perfect’, and disk is currently better at sequential writes. However, this research will show that flash is cheaper now than disk for active data and will become cheaper than disk for almost all applications in the data center. It will show that flash is much better as a foundation for the next generation of big data applications and will become the foundation for the electronic data center.
Can Disk Drives Improve?
Can magnetic drives reinvent themselves, and find ways of reducing latency? Seagate introduced flash as a buffer on each disk as an alternative approach.
However, the uptake of this technology
has been paltry for two main reasons:
- 1/ Buffers are a partial solution, not nearly as good to (say) a PC enduser as all-flash storage as Apple has shown with the success of the all-flash ‘Air’ products.
- 2/ Separate buffers on each disk is a sub-optimum way of designing buffers, both for IO average latency and more important IO latency variance (jitter).
Disk technology is used in consumer PCs and enterprise storage in servers and storage arrays. The disk market for mobile devices (laptops, phones, wearable devices, etc.) is rapidly dwindling as flash takes over, and bulk data requirements are provided in the cloud. Desktop PCs are a sharply declining market with multiple alternatives including VDI and PC cloud services from Google and Microsoft. The high-speed enterprise disks are a rapidly declining market as flash dominates with lower costs of IO performance and lower costs of maintenance by storage administrators and DBAs. The business case for wide-scale investment in performance disks is non-existent, and the only significant market left is capacity disks for low activity workloads, i.e., applications such as archive, some big data applications, etc.
Some investment and innovation continues in high-capacity disk drives. For example, HGST is planning to introduce helium drives with Shingled Magnetic Recording (SMR). This overlaps the tracks and is expected to eventually enable data densities as high as 3 trillion bits per square inch. SMR is designed for continuous writing and erasing rather than random updates, and especially suitable for write-once-read-never (WORN) applications.
The bottom line is that there is no development of performance HDD disks and some limited potential innovation in capacity disks but not sufficient to stop the deployment of the electronic data center.
Economic Drivers for Flash Improvement
The fundamental drivers for flash improvement come from the consumer market. The first introduction of flash in a large-scale consumer product was for the Apple iPod in September 2005, powered by ARM chip technology. It had far less capacity than the ‘classic’ hard-disk alternative iPod but allowed smaller and lighter devices, needed less power and less recharging and was much more resilient when dropped. The ‘Classic’ iPod with a 1.8-inch HDD and up to 160GB of space was finally withdrawn in September 2014 as cloud service offerings made the higher capacities irrelevant.
All mobile devices have used only flash and ARM technology, and increasingly PCs are flash-only. Flash is found in thumb drives, has replaced tape in cameras and is ubiquitous.
The bottom line is that data centers are able to take advantage of the huge flash volumes for the consumer market. Flash technology has improved at a faster rate than Moore’s law, with more than 50% improvement in annual price performance and density. The demand for consumer flash shows no signs of abatement. With relatively little additional investment, flash technologies can be used in the enterprise datacenter. Disk vendor CEO claims that there is not enough money to build enough flash capacity to replace disk drives are simply false – the consumer flash market’s virtual elimination of consumer disk is proof positive. There will be sufficient flash capacity available to enable the deployment of the electronic data center.
Will Flash Be Replaced With Other Technologies?
There has been much discussion about replacing flash with some other type of Non-volative Memory (NVM) technology. The proponents of these technologies usually start presentations at IEEE meetings with the premise that flash has reached the end of the line and cannot be developed further. The technologies are exciting and include MRAM, RRAM (HP’s Memristor is in this category), PCM and racetrack technologies. History teaches us that only two successful major volume memory technologies have been introduced in the last fifty years – DRAM and flash. There have been innumerable also-rans.
These new NVM technologies face two challenges:
- 1/ Understanding exactly how the technologies work and how they can be produced in volume and at high yield; MRAM is in production on low-density chip technology, and may make some inroads into DRAM, but other technologies are still at the university stage and are a long way from volume production.
- 2/ Developing sufficient demand to enable the investment necessary to deploy them on the latest chip technology (and therefore attain the performance gains); the catch 22 of new technologies, the challenge of securing investment to deploy on the latest technology to increase the volume and lower cost in the long run. At the moment, there is no defined killer application which cannot be met with flash.
Flash has a strong future path laid out to 3D technology and has shown that investment has managed to solve the problems that the pundits for new NVM technologies said were impossible to solve. The history is remarkably similar to the continued evolution of DRAM.
MRAM is in limited production, and has a potential role as an alternative for capacitor-protected DRAM. However, flash is also moving swiftly. With atomic writes, the access time between disk and flash is reduced by 10,000 times, from a best of 1 milliseconds to 100 nanoseconds for a line write of 64B. RRAM and PCM technologies have military potential in niche usage, and these technologies may have uses in micro-sensors for the Internet-of-things. However, Wikibon believes that unless a new NVM technology is adopted in consumer products in volume, the continued investment in flash technologies driven by consumer demand will make volume adoption of any NVM alternative very unlikely, and make their adoption in enterprise computing economically impossible.
The bottom line, as Wikibon has stated before, is that flash will be the only NVM technology of importance for enterprise computing for at least the next five years (end of this decade) and very probably for the next decade. Flash, warts and all, is the persistent storage medium for the foreseeable future in the electronic data center.
Flash and Disk Availability Characteristics
Disk drives can crash, and, as the name implies, they crash catastrophically from a user perspective. Most PC users have experienced the impact of a disk crash, and recovery takes a long time and is often incomplete. The same problem exists in storage arrays. Where disks are bound together in RAID groups, the data is not lost if a single disk fails. However, recovery in a RAID environment can take days. In arrays such as the IBM XIV, recovery times are reduced by spreading all the data over all the disks, which improves recovery time at the cost of doubling the storage required.
Flash drives ‘wear’, that is the more times you write data to a flash cell, the higher the probability that a cell will fail. This was a major concern in early flash implementations. However, ‘wear leveling’ software has advanced dramatically and is now implemented in the controllers of solid state drives. Wear leveling is now a problem that NAND flash suppliers have solved and will continue to improve. SSDs are now offered with longer life-time guarantees than disk drives (5-10 years and expected to increase). Flash wear can be monitored and is not catastrophic. There is time to take action if necessary.
The bottom line is that flash drives are much more reliable that disk drives, and will continue to increase in reliability. The average maintenance cost of disk drives is about 18% of the acquisition price per year. For flash drives it is currently about 10%, and is expected to drop. Flash drives can be loaded in hours, compared with the days or months that it takes in a typical migration from one disk-based array to another. The write off-period for flash arrays will be longer and less risky that current disk-drive arrays, which will contribute to the early deployment of the electronic data center.
Data De-Duplication and Compression
De-duplication and compression have been around for a long time, introduced by Microsoft on PCs and NetApp on arrays and now provided by most disk-storage array vendors.
There are three main challenges
for de-duplication and compression on disk-based arrays:
- 1/ De-duplication and compression change the size of the data to be written. The resultant data is very variable, both bigger and smaller than the original. This leads to fragmentation of data on the disk, with complex chains and metadata that are very difficult to manage on slow speed disks;
- 2/ A disk drive is unlikely to be able to support (say) five times the accesses to a disk after data reduction, except for applications very low data access rates (e.g., deep archive applications). Disk drives have very low access densities, which means that de-duplicated and compressed data will have far worse performance;
- 3/ The storage controller overhead for data reduction processing and management is very high, and in traditional two-controller array architectures can itself lead to significant performance impacts, especially when combined with other storage array software such as replication.
Permabit has introduced the advanced data reduction technology for traditional storage arrays, and have recently announced partnerships with EMC, NetApp and others. Wikibon research shows that there is a compelling case to used compression and de-duplication on the flash storage component within hybrid arrays, but few applications can support it on disk-based arrays.
The reason that flash can support de-duplication and compression is that the access density for flash is much higher, 100s of times higher than mechanical disk drives. The overhead on storage and array controllers is still high, and flash storage arrays will have to be designed to reduce the overhead as much as possible.
The bottom line is that flash can support data reduction techniques such as de-duplication and compression as standard, an important contribution in the journey to the electronic data center.
Eliminating Copies of Data by Applications Using the Same Data Source
In disk-based environments, copies of data are made all the time. Deeply imbedded in disk storage practice is avoiding applications accessing the same data on the same drives and avoiding the same database tables being accessed from multiple applications in database environments. For example, a clone of the current production environment is made for the members of the development team. Data is copied and loaded into the data warehouse. Many versions of data are held in Hadoop big data systems. Wikibon estimates that data is typically copied 8-10 times. Often the data copies are a subset – for example, developers may be given a small subset of the production database. The reason is the elapsed time taken to make these copies, as well as the physical space taken.
Snapshots are an important technology for disk storage arrays. Space-efficient snapshots capture the blocks that have changed since the last snapshot, in the same way as a traditional differential backup, and allow rapid rollback to previous versions of data. They are also a very useful type of snapshot for taking logical copies of the same data; however on traditional disk storage the performance characteristics and metadata management largely made these copies useless for active disk-sharing process workflows. Full clones are invariably used if multiple copies are needed for (say) application developers, and often only a subset of the data is used.
Flash has none of the IO density constraints of disk drives. Using space-efficient snapshots together with high-performance metadata, a logical copy of data can be made available to other applications ins, but sharing the same physical data where it has not been changed. For example, the development team at a European investment management company gets a copy of the production database and then publishes the latest full version of this application and data to all the developers, testers and QA. The developers have gone from an IO constrained to a processor constrained development environment – they needed faster processors to improve development time. They have gone from a subset of production to a full production copy, so testing and QA is far more effective. The de-duplication rate in this new environment is well over 10 times. The characteristics of flash mean that the overhead is near zero, and the time to produce a new development copy is reduced by factors of 10 or more.
Another potential example is the development of applications that analyze large amounts of data in real-time and then adjust the operational systems in real time. This type of system is much easier to implement if the data is shared between operational and analytic applications.
The biggest constraint in moving to this type of environment will be persuading senior storage administrators and DBAs, who have grown up with the current constraints of existing arrays, to utilize completely new ways of managing production storage. The biggest constraint for storage vendors with new types of flash arrays will be persuading them that the architecture and metadata management of storage arrays has to be completely different for this new environment.
The bottom line is that management has a significant role in driving attitude change in IT management and IT vendors (software and hardware), necessary for the full deployment of the electronic data center.
Calculating the Cost of Flash Vs. Disk Systems
Back in 2009, Wikibon forecast that performance drives (e.g., 10K & 15K drives) would cost the same as flash drives in 2014. That has turned out to be true. The key question now is when all disk drives systems will be more expensive than flash drives.
In a 2013 study Wikibon looked at the raw technology costs of HDD and SSDs. The data in Figure 2 below was generated using the data and assumptions from that study, adding in the cost of power, space and maintenance, and adding in the potential improvement in practical de-duplication rate that can be achieved for all workloads.
There are two constituents
to decreasing the amount of flash storage required:
- 1/ The data reduction achieved with de-duplication and compression and other technologies; the green line on Figure 2 shows this increasing from an average of 2 to 4 over the five year period (the blue dotted line shows the low level of data reduction that can be achieved on disk-based technology);
- 2/ The level of data sharing that can be achieved, by building large scale-out flash architectures to increase the amount of data sharing; the purple line shows the increase from just over 1 to a factor of 6 as the shared data model is adopted in data centers.
These two factors are multiplicative, which explains the steep drop in cost over time. The all-flash storage vendors often argue that all data can produce data reduction rates of five or higher and show ‘call home’ figures that prove that their arrays achieve that.
The logical flaws in this argument is:
- 1/ Work which does produce high de-duplication rates will be migrated to their storage arrays. It does not mean that all data will meet these levels of de-duplication.
- 2/ The de-dupulication figure will usually include both de-duplicated data and shared copy data (indeed, VDI is mostly copy reduction);
- 3/ The potential for shared copy data is greater that de-duplication and compression, as can be seen in Figure 2.
- 4/ To achieve higher levels of data sharing, the architectures of all-flash arrays and the business practices of data sharing will need to evolve. infrastructure will need to evolve.
Figure 2 below shows the projection of the true cost of raw HDD and SSD technology, with all the costs (except for infrastructure personnel costs) included. It is also important to point out that we are looking at the cost of raw technology. As was discussed earlier, the uplift of storage arrays over raw technology is very high at the moment (10-15x). This ratio will drop over the next five years but will not matter to the final outcome because flash arrays will have the ability to match or exceed these drops in uplift ratio.
Figure 2: Projection of Technology Costs of Capacity HDDs and Flash Technologies 2015-2020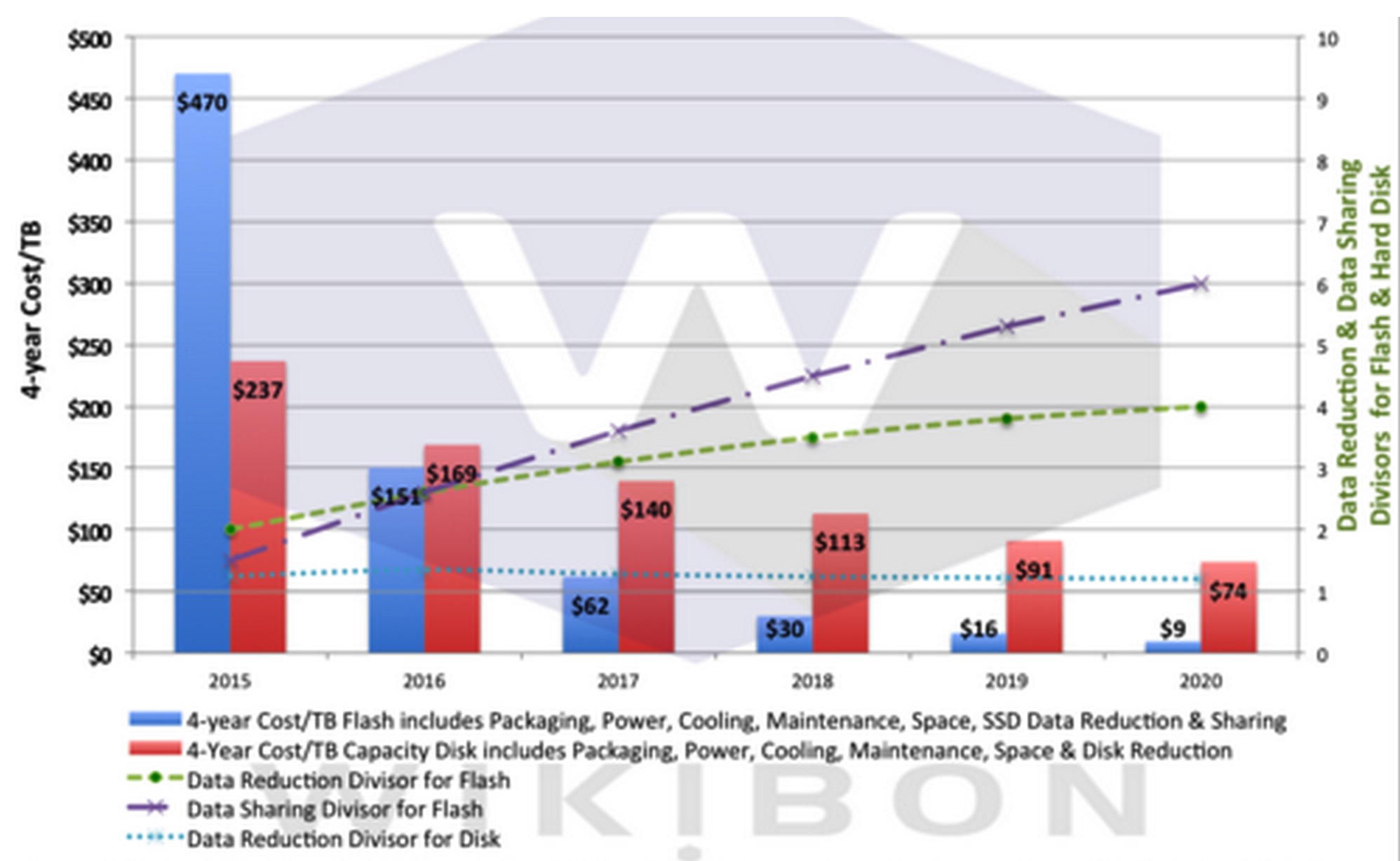
(Source: Wikibon 2015)
The implications for IT, business and IT vendors of Figure 1 are profound. In six years time, the cost of data center storage will be 40 times lower than today, will be flash only, will have higher data transfer and IO rates, and IO densities that are thousands of times greater than today. Most importantly, it will remove IO as a constraint to application innovation, and allow real-time deployment of big data systems.
The bottom line is that the era of the electronic data center is cost justified now, that data sharing is a key metric to optimize, and with speed to deploy advantages it will be a major factor in establishing business differentiation.
Initial Flash Architectures
Wikibon research indicates that there have been four major stages in the development of flash persistent storage array data architectures:
1/ Exploitation of SSDs Within Existing Arrays with SSDs
- Whenever a new technology is introduced, the initial imperative is to minimize the cost of migration by avoiding having to make any changes to applications or the infrastructure supporting them. EMC announced its first flash SSD drives in early 2008, less than three years after the first large-scale consumer introduction into the Apple nano in September 2005. The initial drives were small fast drives and very expensive from a cost/GB viewpoint. These drives were used to release storage volumes that are a bottleneck in applications, especially in databases. The use of these drives was enhanced by the introduction of tiering software such as EMC’s FAST VP that allowed automatic migration of volumes and parts of volumes to flash. This software was effective in utilizing expensive flash resources more efficiently. The value of this software has decreased as flash prices have dropped much faster than disk.
- This initial implementation of flash allowed confidence to grow in flash as a medium for persistent enterprise storage. It allowed lower IO times and higher IO/s for applications. It improved existing applications, sometimes. However, flash was still being used mainly as a buffer in front of disk-drives. The complexity of dealing with occasional very high latencies still exists within this flash implementation, and it is not suitable as a basis for new application design.
2/ Hybrid Architectures
- A number of hybrid architecture storage arrays have been introduced with much higher amounts of flash and where the master copy of data is written through to a disk back-end. As an example, Tintrí introduced a ‘flash-first’ design that writes all data to flash, and then trickles down storage to high-capacity disk as the number of accesses to data decrease over time. EMC with the VNX and others have re-written their controller software to facilitate the adoption of larger amounts of flash storage.
- This approach leads to more consistent IO response times and higher IO/s but still maintains disk as the ultimate storage. This still limits its application to existing applications with small working sets. It is not a sound foundation for entirely new ways of writing applications.
- Because of the foundation of hybrid storage arrays linked to disk drives, it is not a foundation for a modern shared storage architecture.
- Today’s hybrid architectures could migrate to lower performance flash as the backend storage media and address SMB and mid-market requirements.
3/ All-Flash Arrays With Traditional Dual Controllers
- Several all-flash arrays have been introduced over the last few years by a variety of traditional and start-up vendors;
- These have varied from simple very fast flash arrays such as the IBM FlashSystems to arrays using significant software in the dual controllers to provide higher levels of de-duplication and compression, such as Pure Storage;
- These architectures are limited by the dual controller in both function that can be deployed and in the amount of de-duplication that can be achieved.
4/ Scale-out Shared Data Architectures
- This is the subject of the next section, and is key to the adoption of the electronic data center.
Scale-Out Shared Data Architectures
Adopting a shared data philosophy within the data center mandates that the flash persistent storage arrays supporting this deployment have a number of architecture attributes. The four key attributes are listed below, in order of importance:
1/ Scalability
- To allow sharing of data across an enterprise, the storage arrays must scale beyond the traditional dual-controller architecture.
- A scale-out architecture must allow access by all nodes to all the metadata describing the data, snapshots of data and applications accessing the data.
2/ Consistent Latency and Latency Variance
- No HDD system can deliver consistent latency for every IO – all-flash arrays are the only way of providing this capability;
- The array architecture must provide automatic, even distribution of data access load (this cannot be a manual function) to eliminate hotspots;
- This is a prerequisite for QoS for shared data.
3/ Advanced Snapshot Technologies
- With traditional disk arrays, snapshot management is a challenge in production workloads, especially large-scale production workloads. One important challenge is the data density of disk drives to support snapshots;
- With all-flash arrays, the access density of flash allows snapshot copies of data to have potentially the same performance as the original and enables multiple snapshot copies to be made of the original and derivative snapshots. Prerequisite for this are the availability of metadata and metadata management schema that will allow the required performance, and allow knowledge of performance at both the logical and physical abstraction levels.l
- Full-performance, space-efficient writeable snapshots with full metadata support are key to data sharing.
- The management of snapshots must include a full-function catalog describing when copies were taken, how presented, and when they were used by other applications (this function can be within the array or can be provided by external software with APIs to the array).
- Advanced snapshot technologies will completely alter the way that high-performance systems are backed up, allowing specific RPO and RTO SLAs to be adopted dynamically for different applications, and eliminating the requirement for de-duplication appliances.
4/ Advanced QoS
- QoS should ideally allow separation of performance QoS, capacity QoS and level of protection.
- QoS should ideally include minimum and maximum performance on an application basis to map directly to application SLAs.
- QoS should allow a view by physical use of shared data as well as the normal logical use by LUN or equivalent, so as to provide management tools to enable full performance management.
The bottom line is that scale-out architectures with rich metadata support, consistent latency, advanced snapshot technologies and advanced QoS are a prerequisite for fourth generation all-flash storage arrays. These arrays will be an initial foundation of the electronic data center.
Current All-Flash Array Vendor Perspectives
Figure 3 shows the worldwide All-Flash array revenues by vendor, taken from a recent report from IDC.
Figure 3: WW All-Flash Array Revenue by Vendor, 1H14
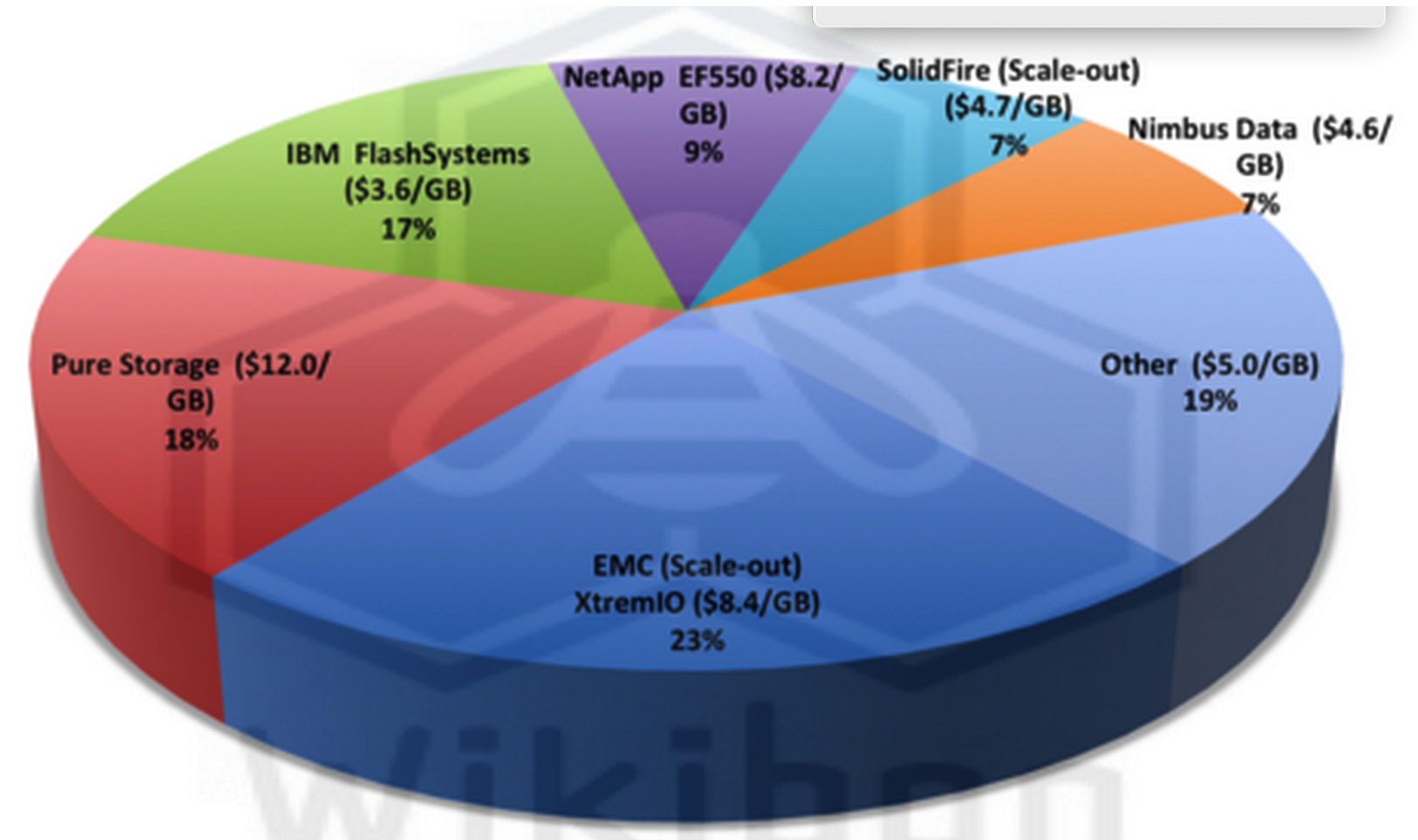
(Source: IDC, 2014)
The data shows that the leading scale-out architectures are EMC (23% share) and SolidFire (7% share) making scale-out architecture about one third of the marketplace. Wikibon predicts that this percentage will increase dramatically over the next few years, as the value of a shared data philosophy permeates IT infrastructure management. This percentage will rise even faster in large-scale enterprises.
No current all-flash array meets all the requirements laid out.
EMC is well positioned with the XtremIO scale-out all-flash array with a fundamentally good data reduction-led (de-duplication & compression) architecture, with good metadata management and data sharing characteristics. EMC has a well established worldwide storage base, and wide distribution channels. Wikibon believes that EMC will grow faster than the overall rate of the all-flash array industry.
SolidFire also has a solid scale-out architecture with good QoS functionality, focused initially on storage service providers.
IBM focuses its FlashSystems mainly on very-low latency high-performance environments. They have been successful in this space but will have to provide a broader portfolio to break into enterprises which follow a shared data philosophy.
Wikibon believes that general purpose dual-controller all-flash array vendors such as Pure Storage and Nimbus will be restricted to IT enterprises that do not accept the benefits of shared data, unless they move to a scale-out architecture.
NetApp has recently announced (September 2014) early shipments of a single-controller version of its FlashRay product, which has been designed by NetApp. It is too early to judge FlashRay.
Wikibon expects new unconventional entrants into the all-flash storage market to emerge.
The bottom line is that the scale-out all-flash sector is set to explode, and enterprises embracing the benefits of a shared data philosophy will benefit greatly from lower IT costs and improved application functionality. This technology will be an important foundation for the electronic data center.
Case Study: Implementing The Electronic Data Center
Wikibon is developing a case study of a financial enterprise managing more than $150 billion in assets that is rapidly completing its journey to the electronic data center. This study will be published separatelyand linked to this research.
Some early quotes from the interviews include:
Production Benefits
- “[A critical business application] is initiated by the market data team at 7:00AM and it needs to be complete by 9:00 AM. Originally, the process took about 90 minutes to run and was available for internal staff and customers at 9:00AM. However, there were any number of issues that could delay the processing which would have a significant impact on the business… The tests suggested that they could reduce the execution time … by 40-50% by moving it to the all flash array. They went live with it a few months later and knocked 60 minutes off an 80 minute process, a huge risk mitigation win for the business.”
Development Benefits
- “The goal set by the head of IT was to be more flexible, to provide [on] demand resources for our development community as they require them. So we provided developers with much greater flexibility”
- “Our primary use for the snapshots are for instantaneous performant copies for our development environment.”
- “So when we moved them all across [to the development environment] we were seeing 7.6 to 1 de-dupe and 2.2 to 1 compression…. That’s 40 copies [of a 2.5TB Oracle database] taking up 5.2TB of space … on the array. So that’s a massive savings for us.”
Operational Benefits
- “From a storage point of view, it’s the first storage platform we’ve put in where we’ve never had any complaints against it.”
- “…we’ve decided that we want to go for an all-flash data center.”
- “The only advice we’d really give is just do it. Storage architecture and storage admin used to effectively be a dark art. There’s none of that now. I could get my 12-year-old daughter to do it. It’s that simple.”
More to come when the journey to the electronic data center study is complete.
Other Future Flash Architecture Trends
Wikibon has written about other trends in flash architectures, in particular with Server SAN or Hyperscale architectures. Functions such as atomic writes will allow flash to become an extension of DRAM, and improve the functionality of large scale database driven applications. This will be another way of improving the productivity of users and organizations, and further integrating big data analytics with operational systems. This trend will also result in many storage services to migrate from the SAN array to the server. This switch will require changes to the functionality of databases and file-systems and is not going to be adopted quickly, but rather as a slow 10-year migration. All-flash arrays will dominate new storage arrays in the early part of the evolution of the electronic data center.
Conclusions and Recommendations
This research shows that flash will become the lowest cost media for almost all storage from 2016 and beyond, and that a shared data philosophy is required to maximize the potential from both storage cost and application functionality perspectives.
Keys trends supporting lower costs with all-flash storage architectures are:
- The continual reduction in flash costs driven by consumer demand for flash – this is inexorable as mobile phones, tablets, phablets and wearable devices continue to roll-out, along with new markets such as the Internet-of-things.
- New scale-out flash array architectures that allow physical data to be shared across many applications without performance impact. This is probably the biggest challenge in educating senior storage executives to reverse the storage management principles of a lifetime.
- New data center deployment philosophies that allow data to be shared across the enterprise, rather than stove-piped in storage pools dedicated to particular types of application. This again will need significant re-education of senior application analysts and architects as to what is now possible with new technologies.
Wikibon recommends that deployment of a data sharing philosophy is an important step in the deployment of the electronic data center.
Action Item: CEOs should be asking three questions of IT.
- 1/ Are there definitive plans to move to an electronic data center?
- 2/ Is the timescale for migration of all mission critical workloads to an electronic data center infrastructure less than 2-years?
- 3/ What are the most important applications that will use the electronic data center to improve enterprise productivity and revenue?
Figure 4: 10-Year Storage Technology Cost Projections 2014-2023 (Cost/TB) 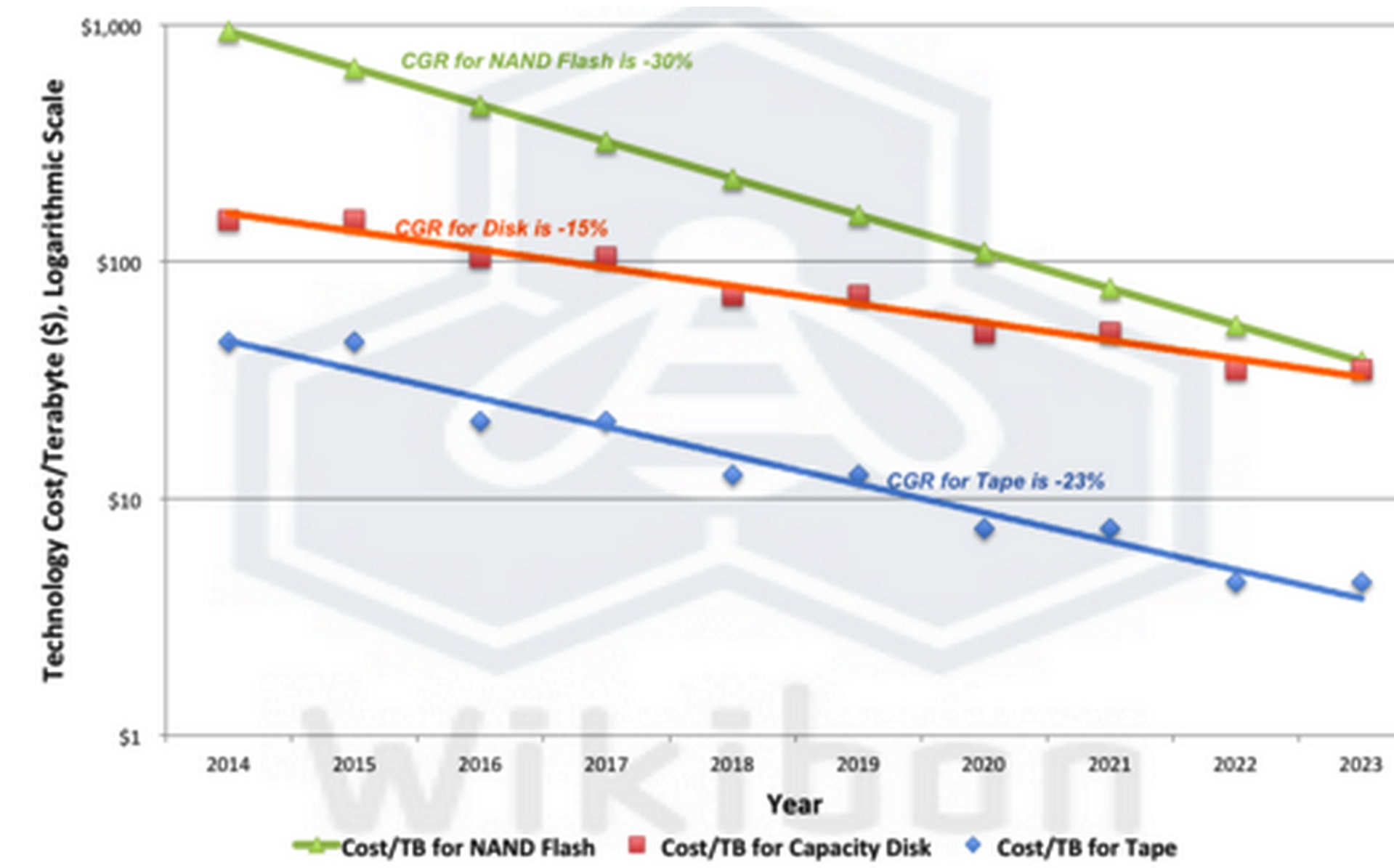
(Source: Wikibon 2014)





 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

